
AI Infra Computing : GPU, DPU, Virtualization, DGX Systems
Comprehensive overview of modern AI infrastructure covering CPU, GPU, and DPU architectures, accelerated computing models, cluster scaling, high-speed networking (InfiniBand and RoCE), storage integration, and power and cooling considerations for AI data centers.
Computation
1. CPU (Central Processing Unit)
- Few powerful cores (4–64+)
- Low latency decision-making
- Optimized for sequential tasks
- Handles OS, orchestration, control logic
Best for:
Operating systems, control plane, general-purpose apps
2. DPU (Data Processing Unit)
Offload, isolate, Accelerate Infrastructure Tasks
- A specialized processor designed to handle data-centric tasks, freeing up CPU/GPU resources for AI workloads.
- Offloads networking, storage, security:
- packet processing
- firewalling
- encryption offload
- Enables zero-trust isolation
- Improves isolation and frees CPU/GPU resources
Best for:
Infrastructure offload, zero-trust environments
NVIDIA BlueField Platform
- BlueField architecture melds a NIC subsystem (based on ConnectX) with a programmable data path, hardware accelerators for cryptography, compression, and reg-ex, and an Arm complex for the control plane.
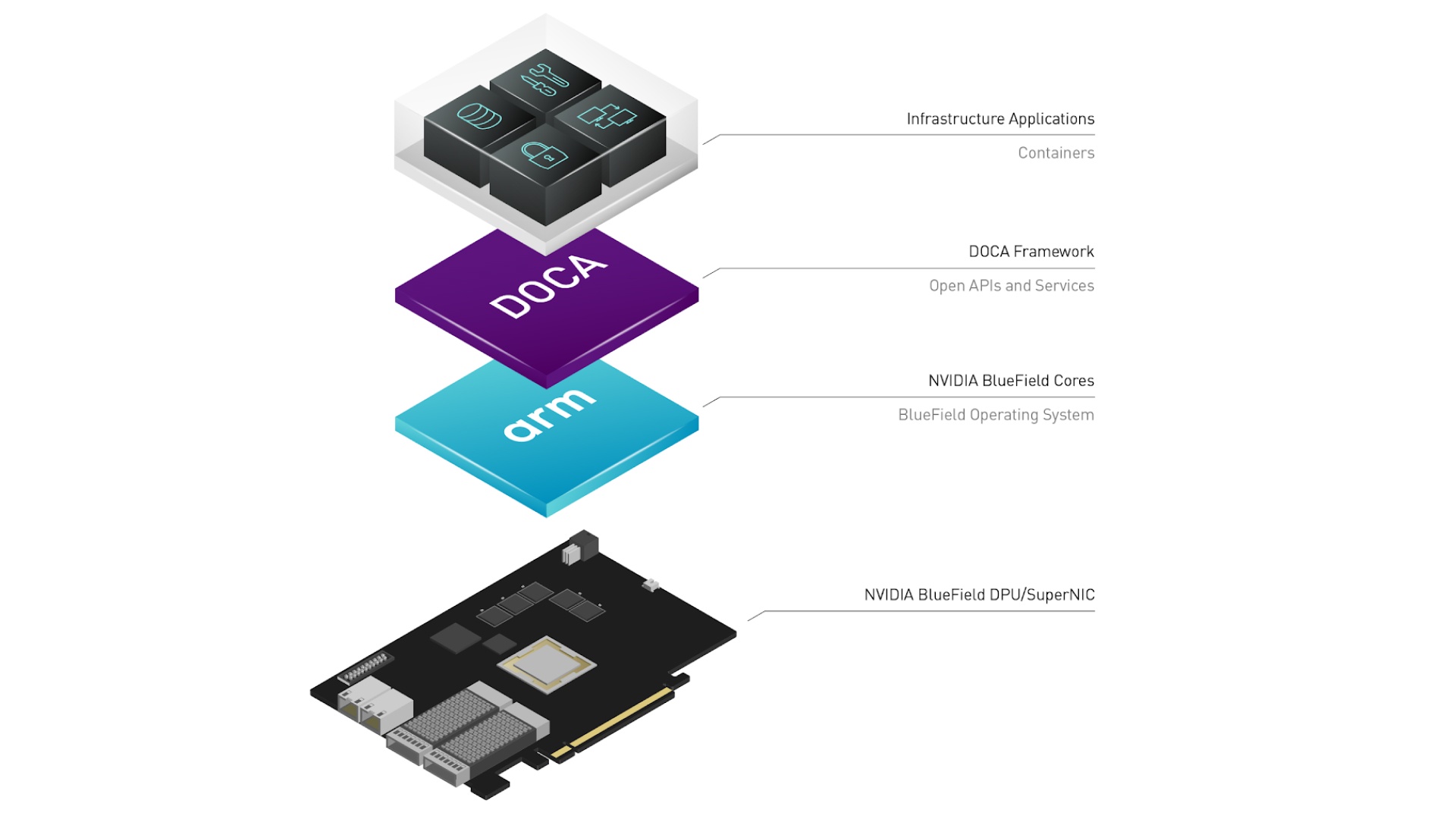
DOCA: NVIDIA BlueField DPU Architecture
Much like CUDA abstracts GPU programming, DOCA abstracts DPU programming to a higher level.

3. GPU (Graphics Processing Unit)
- Thousands of simple cores
- Massive parallelism
- High memory bandwidth & High throughput
- AI training & inference
Best for:
AI training, inference, simulations, rendering
Nvidia Certified Systems:
- Validates Bast Baseline Configuration for AI workloads
- Check for: Manageability, Scalability, Performance, Security
Virtualization – MIG vs vGPU
vGPU(Virtual GPU)
vGPU → VM environments
- Software-based partition
- Hypervisor controlled
- Up to
64partitions (depends on GPU) - Used in VMs, VDI
MIG(Multi-Instance GPU)
MIG → containers / bare-metal
- Hardware-level partition
- Max
7instances - Predictable performance
- Used for AI workloads
If question says:
- Strong isolation
- Bare metal Linux
- AI multi-tenant training Answer → MIG.
GPU Architecture
Core Types
1. CUDA Cores
- General-purpose parallel computation
- Graphics + AI workloads
2. Tensor Cores
- Accelerate AI matrix operations
- Mixed precision compute
- Used in deep learning training/inference
3. RT Cores
- Ray tracing acceleration
- Graphics realism
GPU Architecture based on Workload
Blackwell GPU(B200/300) - AI LLM training and inference, GenAI, AI ResoningHopper GPU(H100, H200) - Data Analytics, Conversational AI, Language ProcessingAda Lovelace GPU(L4OS, RTX 40 series) - Gaming, Ray Tracing, Visualization, AI Powered GraphicsGrace CPU- Arm CPU designed by NVIDIA for AI workloads, paired with H100 in DGX H100- Grace Hopper Superchip (GB): Combines Grace CPU and H100 GPU for high-performance AI compute
- Grace Blackwell Superchip(GB200/ GB300): Combines Grace CPU and Blackwell GPU for AI training and inference
- Nvidia Grace Superchip: 2x Grace CPUs for CPU-only workloads, optimized for AI data processing and analytics
GPU Families (Compute Perspective)
1. RTX Series
- Workstations and visualization
- Not ideal for massive AI training
2. Data Center GPUs
- V100, A100, H100, H200
- Designed for AI, HPC, large-scale compute
NVIDIA DGX (Deep Learning System ) Compute Platforms
Ready to use platform designed specifically for AI, ML, DL workloads.
DGX OS
NVIDIA's customized Ubuntu 22.04-based operating system for DGX Systems.
- NVIDIA-Optimized Kernel for AI, ML, and analytics workloads on DGX systems.
- Latest version DGX OS 7.2.1 released on August 19, 2025
- Comprehensive Software Stack: Includes NVIDIA GPU drivers, CUDA Toolkit, cuDNN, NCCL, DCGM, Docker Engine, and more.
NVIDIA DGX A100
Legacy DGX system for AI training and inference
- 8x A100 GPUs
- 200 Gb/s networking
- ~6.5 kW power
DGX Spark
Desktop version of DGX for AI development and prototyping
- Similar to MacMini but with 4x A100 GPUs
NVIDIA DGX System : H100/H200/ B200/B300
8x H100 GPUs
- 400 Gb/s networking
- ~10.2 kW power
- More memory
NVIDIA DGX SuperPOD
Cluster of DGX systems
- 8× H100 GPUs
- Exascale-class AI compute
- Foundation model training
NVIDIA DGX GB200/ GB300
- 36x Grace CPU + 72 B300 GPUs
- 130 Tb/s NVLink interconnect
- Liquid cooling
- Designed for large-scale AI training and inference workloads
Typical question:
Which solution is suitable for training massive LLMs across multiple racks? Answer: DGX SuperPOD.
NVIDIA AI Platform
Cloud offers pre-configured environments for AI workloads, including NVIDIA VMI (Virtual Machine Image) and NVIDIA AI Enterprise software suite.
1 Accelerated Infra Layer
1.1 NVIDIA VMI(Virtual Machine Image)
- Pre-configured VM images with NVIDIA drivers, CUDA, cuDNN, and AI frameworks
- Available on AWS, Azure, Google Cloud
2 AI Platforms Software Layer
2.1. NVIDIA AI Enterprise
Software suite for AI workloads in enterprise environments
- Includes AI frameworks, tools, and support for NVIDIA GPUs
- 50+ AI frameworks and tools, including TensorFlow, PyTorch, RAPIDS
- Pretrained models and SDKs for computer vision, NLP, recommendation systems
- Optimized for VMware vSphere and NVIDIA-Certified Systems
3. NVIDIA AI Cloud Services
- NVIDIA AI Cloud Services: Managed services for AI workloads, including model training, deployment, and monitoring on NVIDIA GPUs in the cloud.
NVIDIA DGX Cloud
A cloud-based platform for deploying and managing AI applications on NVIDIA GPUs, with support for Kubernetes and containerized workloads.
- Provides access to NVIDIA GPU resources in the cloud for AI training and inference

Nvidia AI Foundry
A cloud-based platform for building, training, and deploying AI models using NVIDIA GPUs, with support for popular frameworks and tools.
- Service that enables enterprises to use data, accelerated computing and software tools to create and deploy custom models that can supercharge their generative AI initiatives.
NVIDIA AI Foundation
A collection of pretrained models, SDKs, and tools for accelerating AI development across various domains
- Provides access to pretrained models for computer vision, NLP, recommendation systems, and more
- Includes SDKs for integrating these models into applications
NVIDIA NeMo
A comprehensive software suite to build, monitor, and optimize AI agents across their lifecycle at enterprise scale.
It provides microservices and toolkits for
- data processing
- model fine-tuning and evaluation
- reinforcement learning
- policy enforcement
- system observability
