
AI Infra Networking: GPU Clusters, InfiniBand, RoCE, and DPU Integration
Fundamental concepts and technologies for networking in AI-centric data centers, including GPU interconnects (NVLink, NVSwitch), high-speed networking (InfiniBand, RoCE), and the role of DPUs (Data Processing Units) in accelerating AI workloads and managing network traffic.
Networking in an AI-Centric Data Center
AI workloads require:
- Ultra-low latency
- High bandwidth
- Deterministic performance
- Scalability across nodes
Networking must support:
- GPU-to-GPU communication
- Storage access
- Cluster management
- Infrastructure monitoring
Distributed training requires:
- High bandwidth
- Low latency
- Efficient collective communication
- Uses:
- NCCL
- RDMA
- InfiniBand
- NVLink
Latency
Time taken for a single data transfer.
Important for:
- Real-time inference
- Synchronization
Throughput
Total data transferred per second.
Important for:
- Large distributed training
- Checkpointing
- Dataset streaming
Network Separation
AI data centers use separate network planes.
1. Compute Network
- GPU-to-GPU communication
- Used for training & distributed workloads
- Technologies:
- InfiniBand
- RoCE (RDMA over Converged Ethernet)
- NVLink (inside node)
- Priority: Ultra-low latency & high throughput
2. In-Band Management - Network
- Ultra-low latency
- Lower bandwidth, higher latency than compute fabric
- Critical for cluster operations and monitoring
- Technologies:
- SSH
- Job scheduling (Slurm)
- Kubernetes traffic
- DNS, cluster APIs
- Priority: Reliability and availability
3. Out-of-Band Management Network
- Always available even when server is offline
- Remote power control
- Remote console (IPMI, Redfish)
- Priority: Always-on access for management and recovery
4. Storage Network
- High throughput for dataset access and checkpointing
- Technologies:
- NVMe-oF (NVMe over Fabrics)
- Parallel file systems (Lustre, BeeGFS)
- Often uses RDMA for low latency
- Priority: High bandwidth and low contention
DMA (Direct Memory Access)
Direct memory access without CPU copying data.
- Bypasses CPU for data transfer
- Reduces latency
- Increases throughput
- Used in GPU interconnects and storage access
- Enables GPUDirect for efficient data movement
- Critical for high-performance AI workloads
- Supports zero-copy transfers between GPU and network/storage
RDMA (Remote Direct Memory Access)
- Across servers Direct GPU memory access over network
- Memory access across hosts
Traditional Networking
CPU handles:
- Packet processing
- Memory copying
- Interrupts
RDMA
- Bypasses CPU
- Direct memory access across hosts
- Reduces latency
- Reduces CPU utilization
- Increases throughput
InfiniBand vs Ethernet
1. Ethernet
- General-purpose networking widely used
- Higher latency (~10–100 µs typical)
- Uses
TCP/IPstack - Commodity hardware
- Widely supported
2. InfiniBand
High throughput ,low latency with low CPU overhead for connecting to Storage
- Ultra-low latency (1–2 µs)
- Uses
Native RDMAStack to access remote memory directly without CPU involvement - Used in large HPC / AI clusters: over 50% HPC clusters use InfiniBand
- HCA (Infiniband Network Interface Cards): allows hardware offload of RDMA operations
- Managed by Open Subnet Manager (SM).
Examples:
- NVIDIA Quantum-X 800 Infiniband switch for high-performance InfiniBand-based AI
3. RDMA over Converged Ethernet (RoCE)
RDMA + Ethernet: Enables
RDMAover Ethernet
- Open source alternative to InfiniBand
- More flexible than infiniBand
- Cheaper Enterprise-friendly
- Used in enterprise AI clusters
NVIDIA hardware:
- Spectrum switches (Ethernet) + BlueField DPUs support
RoCEfor high-performance Ethernet-based AI clusters - Nvidia Quantum-X 800 Infiniband switch for high-performance InfiniBand-based AI clusters
GPU Interconnects (Compute Fabric)
1. PCIe
- Standard connection
- Higher latency
- Limited bandwidth (16–32 GB/s)
- Not ideal for multi-GPU scaling
2. NVLink Chip-to-chip interconnect
GPU to GPU inside same node → NVLink
- High-speed
GPU-to-GPUcommunication inside server - Up to 600 GB/s
- Faster than PCIe
- Enables multi-GPU scaling
- Uses NVSwitch for scale
3. NVSwitch Fabric
Connects multiple GPUs in large systems
- Enables full bandwidth communication across large GPU arrays
- Used in DGX SuperPOD to connect 8× H100 GPUs
- Provides non-blocking, high-speed interconnect for large multi-GPU systems
4. GPUDirect RDMA
GPU to GPU across nodes → GPUDirect RDMA
- Works across hosts
- GPU-to-GPU or GPU-to-NIC
- data transfer for HPC, AI clusters
- No CPU involvement = Ultra-low latency
5. GPUDirect Storage
Storage device ↔ GPU memory
- Works within a host
- High-throughput GPU data loading from
NVMe/RAID/parallel storage - Avoids system memory bottleneck by bypasses OS, system memory & CPU
- High-bandwidth I/O for feeding large datasets into GPUs
GPU & Network Management with Kubernetes Operators
NVIDIA GPU Operator
Open source Kubernetes operator for managing NVIDIA GPU resources in Kubernetes clusters.
-
Simplifies GPU management in Kubernetes environments, enabling seamless deployment of AI workloads on GPU-accelerated Kubernetes clusters.
-
Sits on Top of Kubernetes to ensures GPU resources are available and properly configured for AI workloads running in Kubernetes
-
Supports both on-prem and cloud Kubernetes clusters
-
Automates deployment and management of NVIDIA GPU drivers, device plugins, and monitoring components in Kubernetes
- NVIDIA Driver installation and updates
- NVIDIA Container Runtime support for GPU-accelerated containers
- **NVIDIA K8 Device Plugin ** for exposing GPU resources to containers
- GPU resource monitoring and metrics collection
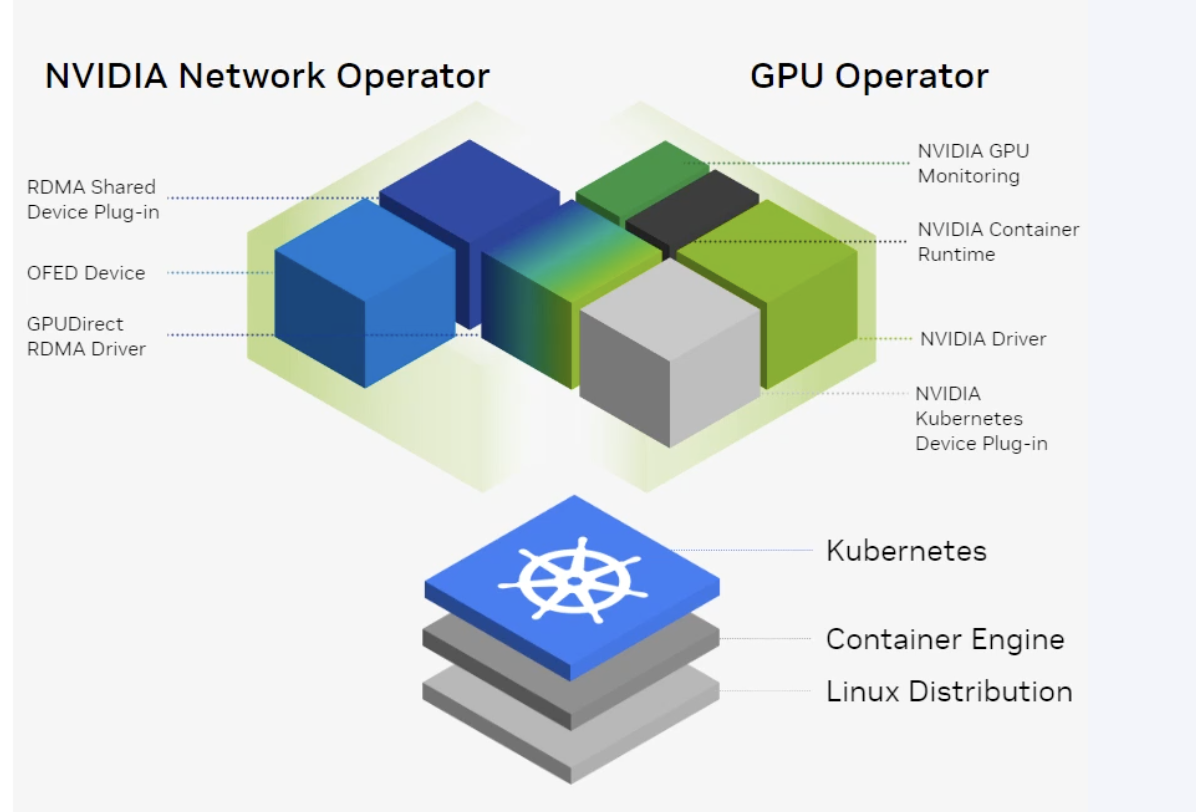
NVIDIA Network Operator
Kubernetes operator for managing NVIDIA network resources in Kubernetes clusters.
-
Manages NVIDIA network resources (InfiniBand, RoCE) in Kubernetes environments
-
Ensures high-performance networking for AI workloads in Kubernetes clusters
-
Works along with GPU Operator to provide comprehensive GPU + network management for AI workloads in Kubernetes
-
Network Operator Components:
- MLNX OFED Drivers: Installs and manages Mellanox OFED drivers for InfiniBand/RoCE support
- K8 RDMA Shared Device Plugin: Exposes RDMA network resources to Kubernetes workloads
- NVIDIA Peer Memory Driver: Enables GPU peer-to-peer memory access across nodes for high-performance networking