
Linear Regression Explained: Single Variable and Multivariate Models with Gradient Descent
Learn linear regression in machine learning, including single-variable and multivariate models, hypothesis function, cost function (MSE), gradient descent optimization, feature scaling, assumptions, and real-world implementation examples.
Logistic Regression for Classification: Concept, Sigmoid Function, Cost Function, and Implementation
telc A2 – Hörverstehen (Listening) 🎧
📐 Linear Regression
Linear regression is a supervised learning algorithm used to predict a continuous output variable based on one or more input features.
- It is widely used for prediction, forecasting, and as a baseline model.
- It assumes that the relationship between inputs and output is linear.
When to Use Linear Regression
Linear regression is ideal for:
- Price prediction
- Trend analysis
- Baseline modeling
- Interpretable relationships
- Fast and simple forecasting
It is often used as a baseline before trying more complex models.
Key Assumptions
Linear regression works best when:
- The relationship is approximately linear
- Errors are independent
- Variance of errors is constant
- Residuals are normally distributed
Understanding these assumptions is important for reliable modeling.
🧮 Training Set
Training Set is the Data that is fed to Leaning Algorithm.
The Learning function outputs a hypothesis function
- = inputs
- = expected output
- = Row in Training Set: single training example
- = i-th training example
- = Number of training examples - rows in training set
- = Number of features - columns in training set
Example: 🏠 House price
| Size (x₁) | Rooms (x₂) | Price (y) |
|---|---|---|
| 50 | 1 | 150 |
| 80 | 2 | 230 |
| 120 | 3 | 310 |
- 📏 → size of house
- 🛏 → number of Rooms
- = 3 training examples
- = 2 features
In machine learning, it’s often not who has the best algorithm, but who has the most data.
Testing several learning algorithms while increasing the training set size.
The key findings:
- Different algorithms often performed similarly.
- Performance improved steadily as training set size increased.
- An “inferior” algorithm with more data often outperformed a “superior” algorithm with less data.
More data helps when:
- Use a rich model → low bias
- Use a massive dataset → low variance
If both are true, then:
- Training error is small
- Test error is close to training error
- Test error is also small
1. Your input features must contain enough features to predict accurately.
Given only the features , could a human expert confidently predict ?
- If yes, then the problem likely has enough signal.
- If not, no amount of data will fix it.
2. Use a High-Capacity (Low-Bias) Model
You need a powerful learning algorithm, such as:
- Logistic regression with many features
- Linear regression with many features
- Neural networks with many hidden units These models have many parameters and can represent complex functions.
This helps ensure low bias.
3. Use a Very Large Training Set
If:
- The model has many parameters
- The training set is much larger than the number of parameters
Then overfitting becomes less likely.
This helps reduce variance.
💡 Hypothesis
Function that maps input to output is called Hypothesis function.
Supervised learning works like this:
Training Set → Learning Algorithm → Hypothesis Function
The algorithm outputs a function called: h (hypothesis)
- = hypothesis, trained Algo that can map to
Finding
Our goal is to find the best values of that minimize prediction error.
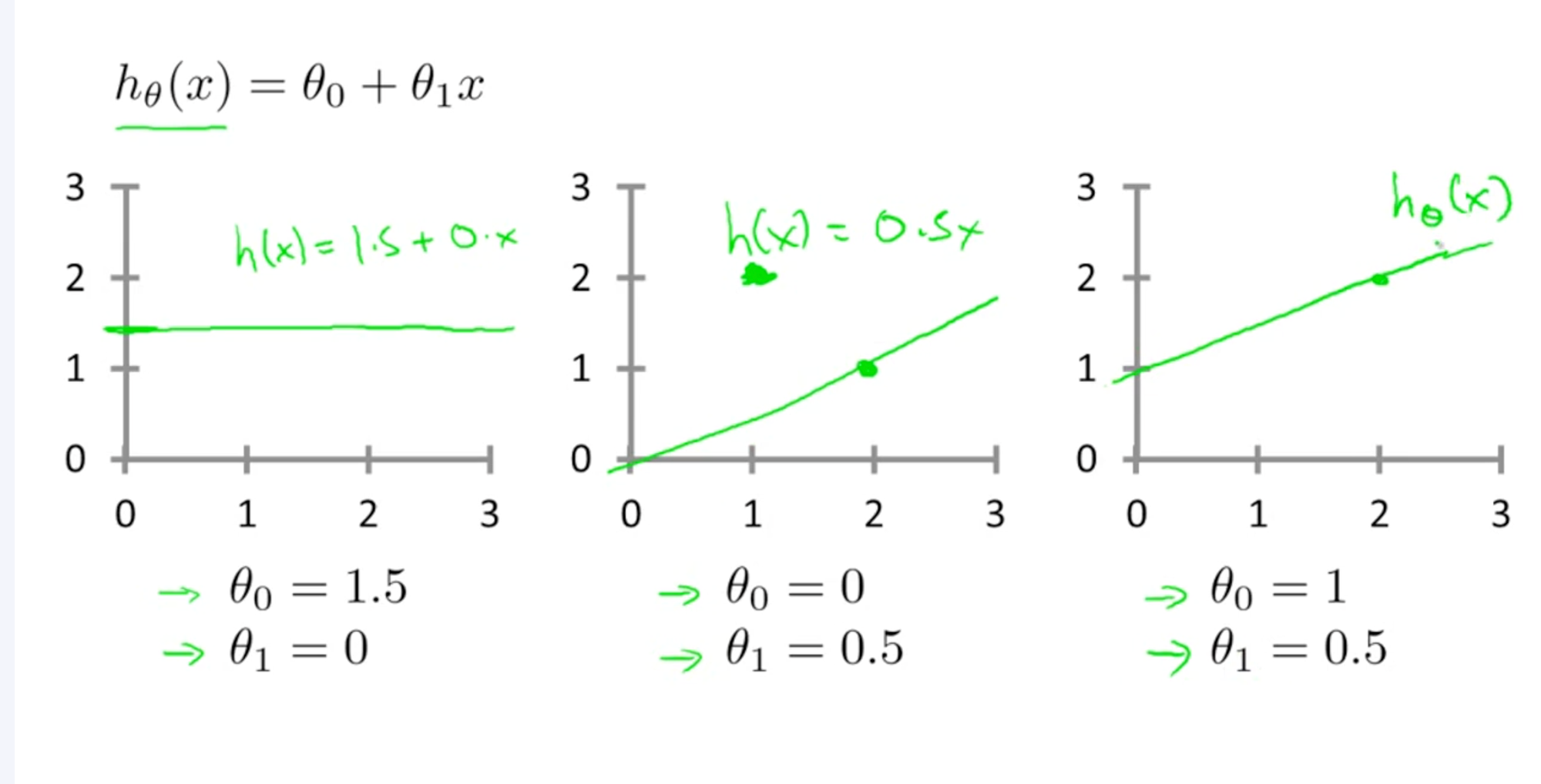
1. Single Variable Linear Regression :
Linear regression is method of finding a Continues linear relationship between Y and X
When there is only one feature, the model is:
This represents a straight line, where:
- = is the predicted value
- = is the input feature
- = is the Y intercept
- = is the slope of line
Example:
-
→ line passes through origin
-
→ horizontal line
2. Multi Variate Linear Regression:
Linear regression with multiple variables
For multiple features:
Matrix form:
Parameter Vector
Target Vector
This form is computationally efficient.
Calculating Hypothesis Function
Using Closed-form solution:
- : Base price of house
- : Price increase per unit size
- : Price increase per additional room
Final Hypothesis Function:
Model Inference
Test For:
- Size = 100
- Rooms = 2
Predicted price = 280
💰 Cost Function ()
How bad are our guesses?
Goal of the algorithm is to choose & such that come close to .
- Minimize thus minimize Error
- Used to measure how well the model performs
Goal is to for a given hypothesis
Find that minimizes
Mean Squared Error Cost Function (MSE)
The squared error works well for regression problems because it:
- Penalizes large errors
- Is mathematically convenient
- Produces a convex function
The cost function is defined as:
Where:
- = number of training examples
- = prediction for given input
- = actual value for given input
The objective is to minimize this function.
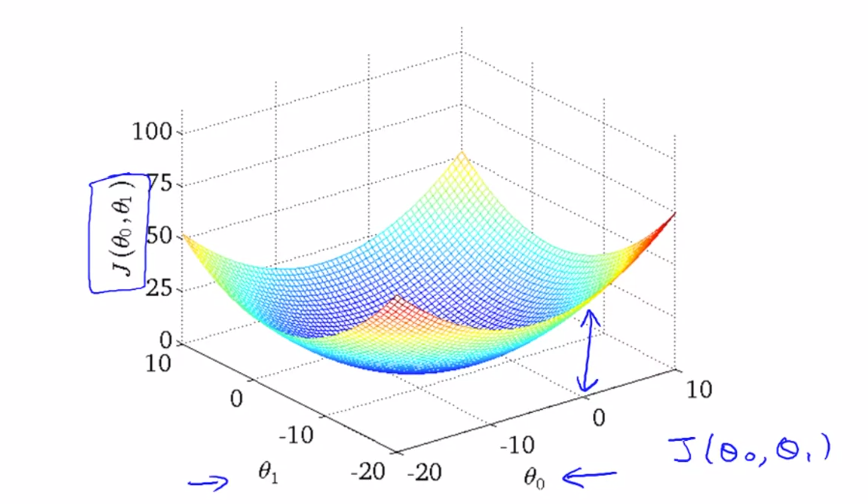
Plotting Cost Function
One Feature () and Two Parameters (, )
Parabola
- as Y-Axis
- as X-Axis
3D Parabola
-
as Z-Axis
-
as X-Axis
-
as Y-Axis
Two Feature () and Three Parameters (, , )
h = $\theta_0 + \theta_1 x_1 + \theta_2 x_2
That lives in 4 dimensions impossible to visualize
J(, , ) as W-Axis
- as X-Axis
- as Y-Axis
- as Z-Axis
Contour Figure ⛰️
Contour plot is seeing surface plot passing through a horizontal 2D clip plane
Each circle represents:
- All points that have the same height = Cost J(θ).
In the contour plot:
- X-axis →
- Y-axis →
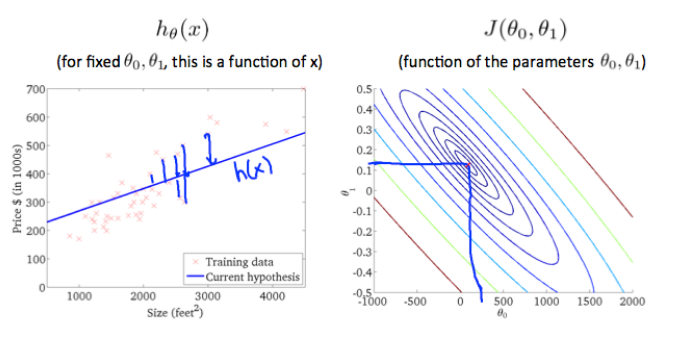
Why Contour Plot is Circular?
Contour Plot is Circular because Cost function is Convex.
- Circle represent all points that have the same height.
- Smaller circles → smaller cost
- Larger circles → larger cost
Gradient Descent Moves towards the center of the contour plot where cost is minimum.
- It moves perpendicular to the contour lines because that is the direction of steepest descent.
🎢 Gradient Descent
Gradient descent is an optimization algorithm used to minimize the cost function by iteratively moving towards the minimum.
That’s just a fancy name for:
Try numbers → see error → improve numbers → repeat.
Works like
- Start somewhere
- Just like going down from a hill.
- Look around and find local minima and keep on going down repeat till find optimal solution.
- Multiple minima can be found
Start somewhere → Take steps downhill → Reach minimum
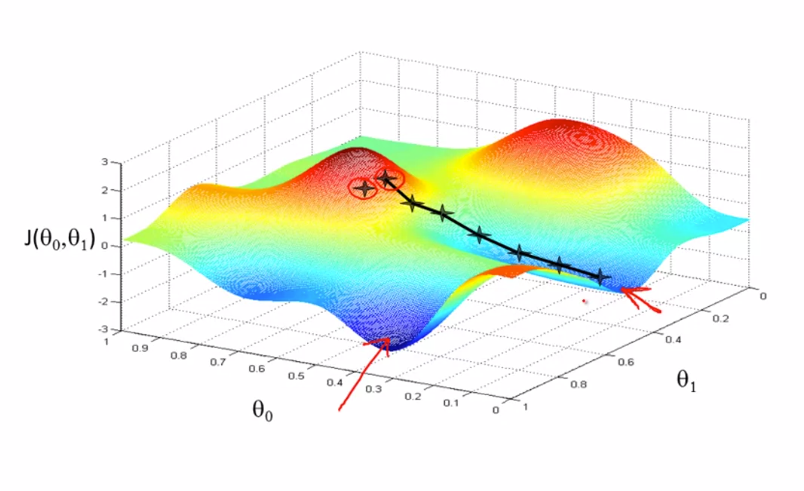
Algorithm: Single Variant Linear Regression
For feature index j= 0, 1 repeat until convergence
For
- Simultaneous compute , and store in temp values
- Simultaneous Update ,
Where:
- Learning Rate, How big steps we take down hill
- is the parameter index
- Assignment Operation eg a= a+1
- Truth Assertion eg a==a
This process is repeated until convergence.
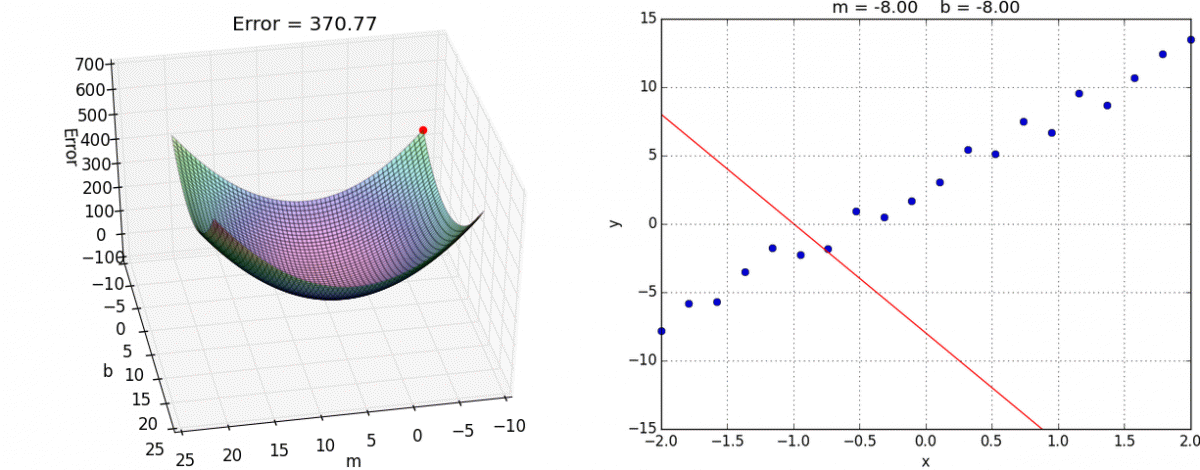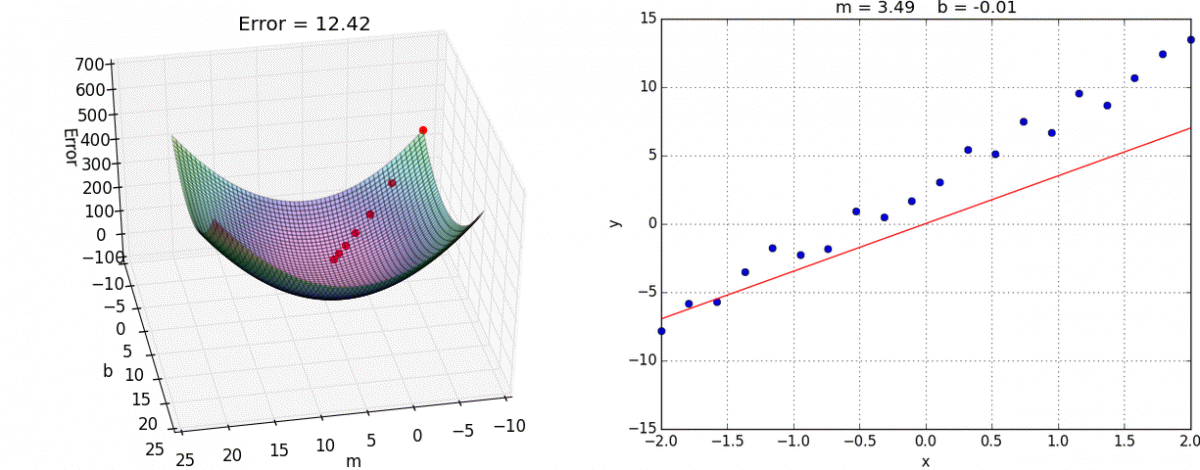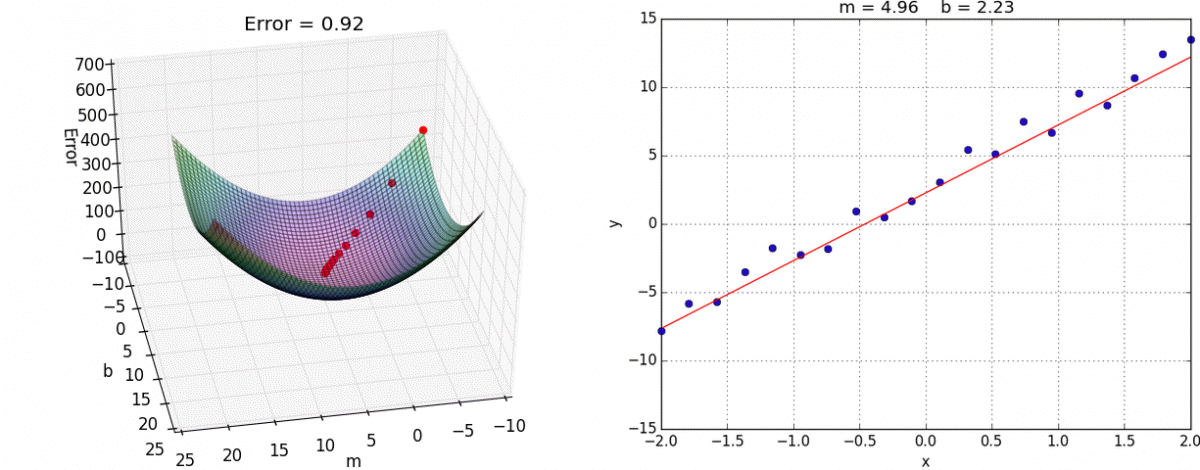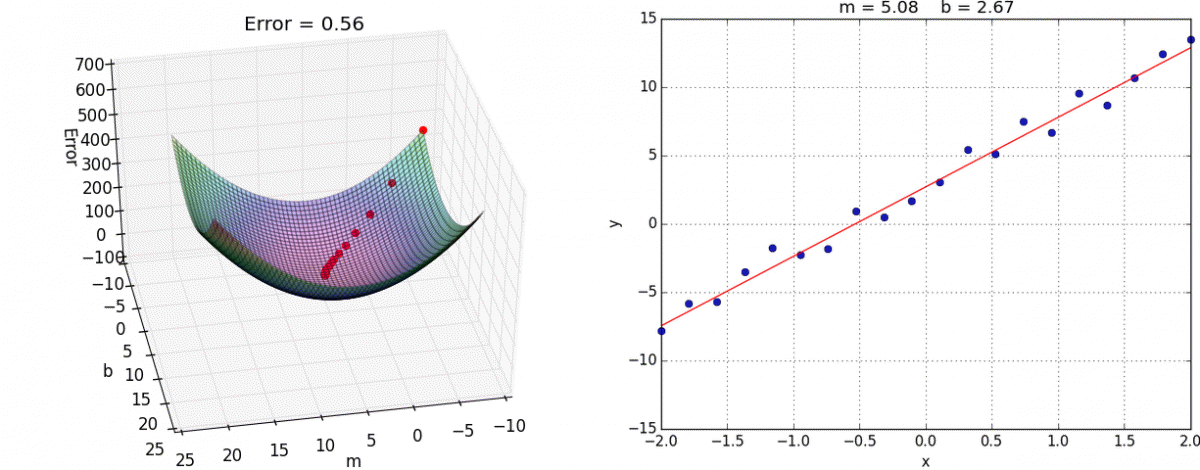
Algo: Multivariate Linear Regression
Steps:
- For feature index j= 0,1,....n repeat until convergence
For
- Simultaneous Compute and store in temp values
- Simultaneous Update
Final Hypothesis Function
Which is equivalent to:
Learning Rate ()
Alpha defines rate of Learning
The update rule is:
Or Simplified
- Small → slow learning
- Large → overshooting the minimum
- Proper → fast convergence
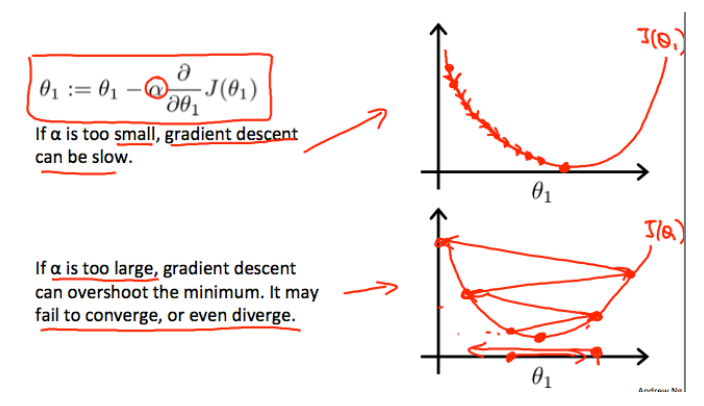
Deciding Learning Rate ()
Plot the cost function, over the number of iterations of gradient descent.
If decreases every iteration, then you are probably using a good learning rate.
- Smooth Steadily decreasing
- Flattening near minimum
- No wild jumps & no upward trend
# Good Learning Rate
|
|\
| \
| \
Cost | \
| \____
|
+----------------
Iterations
If J(θ) continuously increases then you probably need to decrease .
- Reason: Large causes overshooting the minimum, leading to divergence or oscillation.
- Fix: Reduce learning rate.
|
| /
| /
Cost | /
| /
| /
+----------------
Iterations
If J(θ) decreases but very slowly, then you probably need to increase
- Reason: Small causes slow convergence, taking many iterations to approach the minimum.
- Fix: Increase learning rate.
Cost
|
|\
| \
| \
| \
| \______
+----------------
Iterations
If J(θ) oscillates, then you probably need to reduce and scale features.
- Reason:
- Large leading to oscillation around the minimum.
- Features are on different scales,
- Fix: Reduce learning rate and apply feature scaling t
Cost
|
| /\ /\ /\
| / \ / \ / \
| /
+----------------
Iterations
Debugging Learning Rate ()
| Behavior | Problem | Fix |
|---|---|---|
| Cost increases | α too large | Reduce α |
| Oscillates | α too large | Reduce α + scale |
| Very slow decrease | α too small | Increase α |
| No improvement | Features not scaled | Apply scaling |
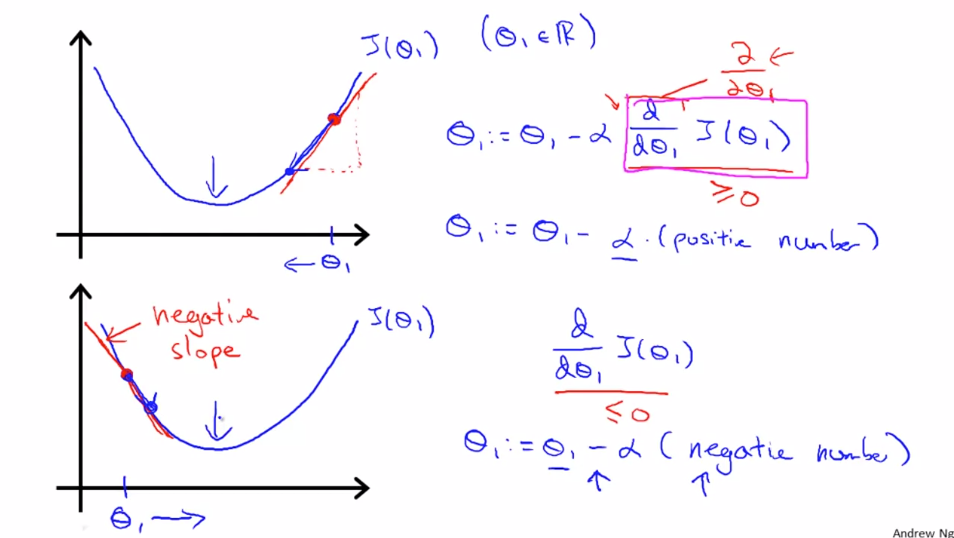
Derivative Term
Derivative terms defines rate of change of Cost function wrt
- At local minima Derivative Term is = 0.
-
Derivative term automatically takes small step when it starts to converge towards local minimal. Having a fixed alpha helps
-
Derivative term automatically converge towards its local minima from both +ve and -ve slopes:
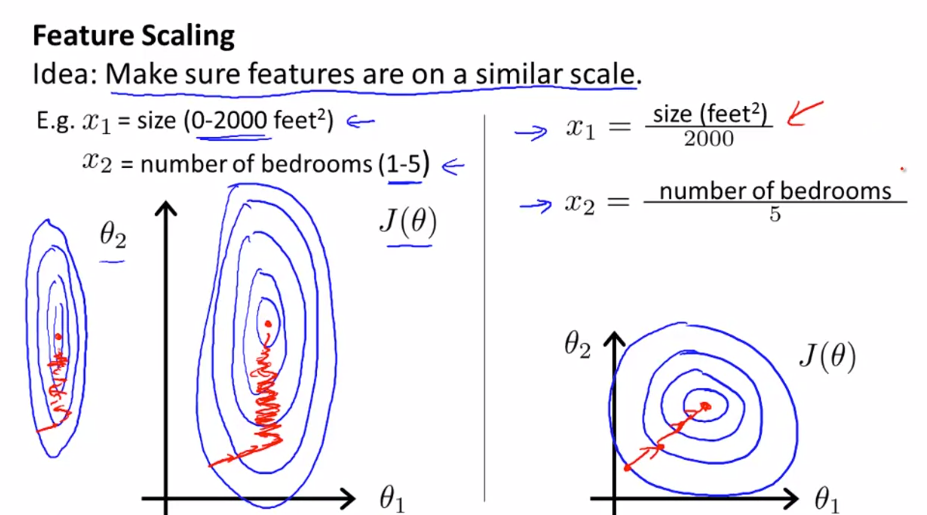
Feature Scaling
Feature scaling helps to make the cost function more circular, which allows gradient descent to converge faster.
- Make sure feature are on same scale otherwise contour will be skew elliptical.
- Try to get feature into
- Ideally should be withing range
Problem
Difference in scale of features can create skew ellipse in cost function.
- example:
- Size of house (0-1000) vs Number of rooms (1-10)
A skew ellipse will have a long axis and a short axis.
- Gradient descent will oscillate across the long axis and take a long time to converge to the minimum.
📏 Solution
1. Min-Max Normalization
This is done by subtracting the minimum value of the feature and dividing by the range (max - min).
- Scale features to [0, 1]
2. Mean Normalization:
This is done by subtracting the mean of the feature and dividing by the range (max - min).
- Scale features to have mean 0 and range [-3, 3]
Alternatively
Where:
- = mean of feature = Avg(X)
- = standard deviation = max(X) - min(X)