
Normal Equation in Linear Regression: Formula, Intuition, and Comparison with Gradient Descent
Support Vector Machines (SVM): Maximizing Margins for Robust Machine Learning Models
Bias-Variance Dilemma
Ideally, one wants to choose a model that both accurately captures the regularities in its training data, but also generalizes well to unseen data.
🔬 Diagnosing Bias vs. Variance
When a model performs poorly, the key question is:
Is the problem bias or variance?
- High bias → underfitting
- High variance → overfitting
Our goal is to find the balance between the two.
Effect of Polynomial Degree
As we increase the polynomial degree :
Training error
- Generally decreases
- Higher-degree models fit the training data better
Cross-validation error
- Decreases initially
- Then increases after some point
- Forms a convex (U-shaped) curve
This behavior helps us diagnose bias vs. variance.
🦎 High Bias (Underfitting)
The model is too simple to capture the underlying pattern of the data
Characteristics:
- Model is too simple
- Fails to capture structure in the data
Problem:
- Poor training performance
- Poor Test performance
And importantly:
Interpretation:
- The model performs poorly everywhere
- Adding more data usually does not help much
- Increasing model complexity may help
🪱 High Variance (Overfitting)
model is too complex and starts fitting the training data perfectly
- Model can bend heavily to pass through every training point.
Characteristics:
- Model is too complex
- Fits noise in the training data
Problem:
Low training error ie. good training performance
Poor test performance lead to poor performance on unseen data.
- Poor generalization to new data
Interpretation:
- Model performs very well on training data
- Performs poorly on unseen data
- Large gap between training and validation error
Solutions
- Use Regularization term to add Penalty for features
- Reduce model complexity:
- Reduce Number of Features: Manually select important features
- Remove irrelevant variables
- Use automated model selection methods
Visual Summary (Conceptual)
As degree of polynomial increases:
- steadily decreases
- decreases, then increases
Low → High bias
High → High variance
Middle → Good balance
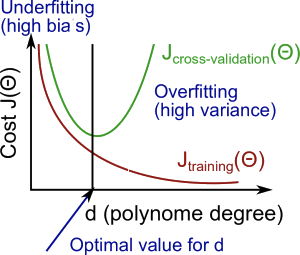
Practical Diagnostic Rule
| Situation | Diagnosis | ||
|---|---|---|---|
| Both high and similar | High | High | High bias |
| Large gap (train low, CV high) | Low | High | High variance |
| Both low and similar | Low | Low | Good fit |
Bias vs Variance Summary
| Concept | Meaning | Cause | Effect |
|---|---|---|---|
| High Bias | Model too simple | Too few features | Underfitting |
| High Variance | Model too complex | Too many features | Overfitting |
Regularization techniques
Used to make reduce variance and solve problem of Overfitting
-
Instead of removing features, keep them all but reduce parameter sizes.
-
Regularization adds a penalty term to the cost function to discourage complexity.
-
Regularization helps prevent overfitting by keeping the model simpler.
-
The regularization parameter λ controls the strength of the penalty. A larger λ means more regularization.
Lasso vs Ridge
| Feature | Lasso (L1) | Ridge (L2) |
|---|---|---|
| Penalty | Sum of absolute values | Sum of squares |
| Effect | Can shrink some coefficients exactly to 0 → feature selection | Shrinks coefficients but rarely to 0 |
| Use Case | Many irrelevant features | Prevent overfitting, keep all features |
Instead of removing features, keep them all but reduce parameter sizes.
The idea:
- Large weights → complex model
- Small weights → smoother model
🔹 Lasso Regression (L1 Regularization)
Lasso: Cost = MSE + λ * sum(|θ|)
- Lasso (L1) can shrink some coefficients to zero, effectively performing feature selection.
In standard linear regression, the cost function is:
Lasso adds a penalty proportional to the sum of absolute values of the coefficients:
Where:
- = regularization strength
- = absolute value of parameter
- (bias) is usually not penalized
🏔️ Ridge Regression (L2 Regularization)
Ridge: Cost = MSE + λ * sum(θ^2)
- Ridge (L2) shrinks coefficients but does not set them to zero.
The standard linear regression cost function is:
Ridge adds a penalty proportional to the sum of squared coefficients:
Where:
- = regularization strength
- = model parameters
- (bias) is usually not penalized
Key Insight
- Bias is about model simplicity.
- Variance is about model sensitivity to data.
Good model selection is about finding the degree that minimizes:
while avoiding both underfitting and overfitting.