
AWS Database Services
Overview of available AWS DB Services, their types, use cases, pros and cons.
Database Service
DB by Use Cases
| Database Type | Use Cases | AWS Service |
|---|---|---|
| Relational | Traditional applications, ERP, CRM, e-commerce | Amazon Aurora , Amazon RDS , Amazon Redshift |
| Key-value | High-traffic web apps, e-commerce systems, gaming applications | Amazon DynamoDB |
| In-memory | Caching, session management, gaming leader boards, geospatial applications | Amazon ElastiCache , Amazon MemoryDB for Redis |
| Document | Content management, catalogs, user profiles | Amazon DocumentDB (with MongoDB compatibility) |
| Wide-column | High scale industrial apps for equipment maintenance, fleet management, and route optimization | Amazon Key spaces |
| Graph | Fraud detection, social networking, recommendation engines | Amazon Neptune |
| Time series | IoT applications, DevOps, industrial telemetry | Amazon Time stream |
| Ledger | Systems of record, supply chain, registrations, banking transactions | Amazon Quantum Ledger Database (QLDB) |
Relational Database for OLTP (Online Transaction Processing)
Data Stored as Table-> Record-> Field(Value+ Primary Key)
1. Amazon RDS(RELATIONAL DATABASE SERVICE)
Manage relational databases in the AWS Cloud to support SQL
- Manged DB: Automatic Provision & Patching with Monitoring Dashboard
- Come in free tier
- Scale Vertically & Horizontally
- Backed by EBS(gp2, io1)
- Data is encrypted when stored & transit(sent/ receive)
- Disaster recovery using Multi AVZ replica
- Continuos Backup to S3
- Transactions Logs backup every
5 Minute - Point & Time Recovery:Disaster Recovery upto
5 Minute - Daily full backup of DB which store up to
35 days
- Limitations
- Cant do SSH to DB
- Does not support active-active configuration with cross-region support.

Supported RDBMS(Relational DBMS):
| DB | Port | IAM |
|---|---|---|
| Aurora | 5432 (if PostgreSQL compatible) or 3306 (if MySQL compatible) | |
| PostgreSQL | 5432 | |
| MySQL | 3306 | |
| MariaDB | 3306 (same as MySQL) | |
| Oracle RDS | 1521 | Does not support IAM |
| MSSQL Server | 1433 |
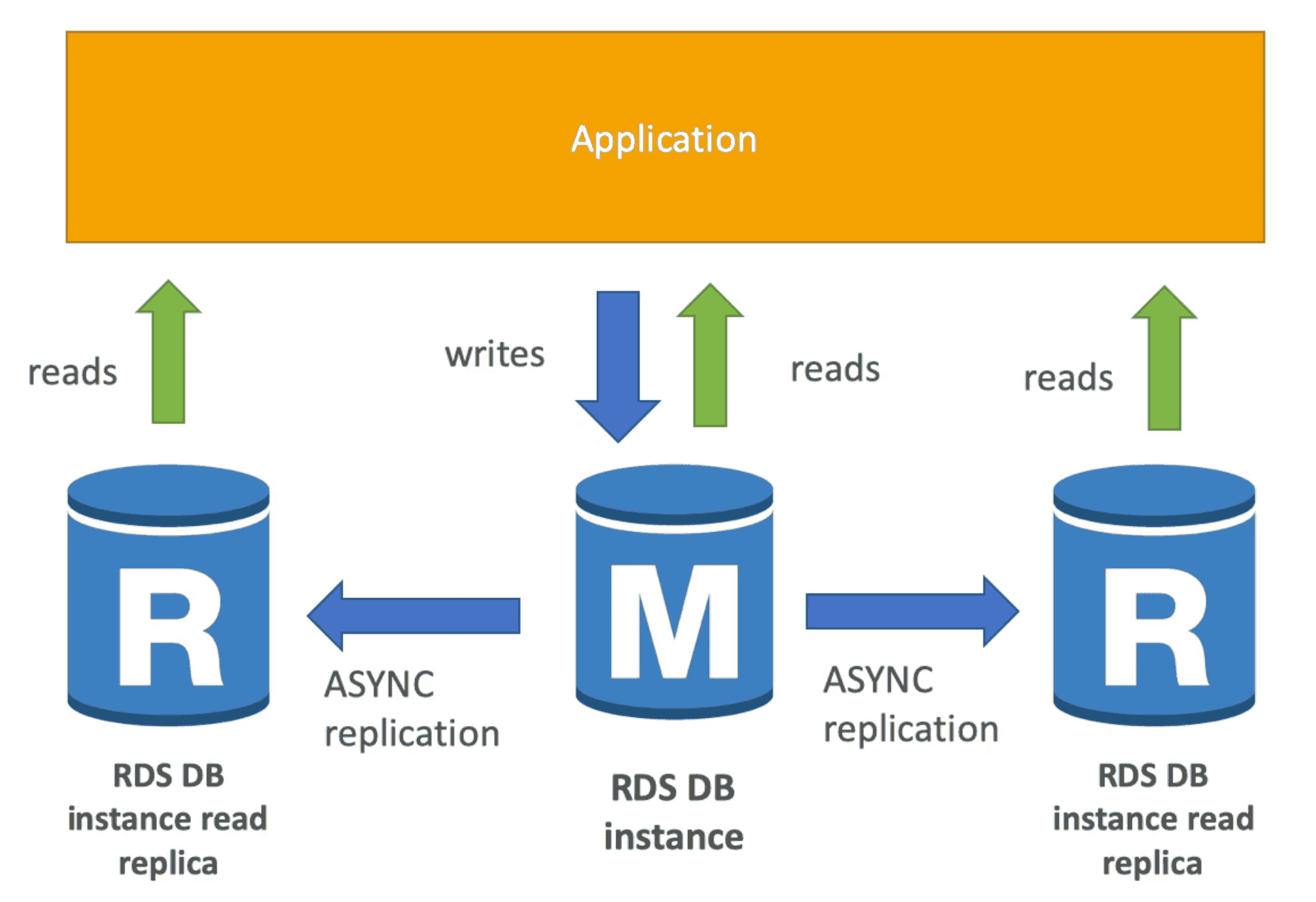
Read Replica
AsynchronousReplication of DB to read replicas to scale read workload
- Up to 5 read replicas per source DB (Aurora is different: 6 storage copies across 3 AZs, up to 15 Aurora Replicas — see Aurora section)
- Supported: Within AZ, Cross AZ, Cross Region
- Cross AZ replication Traffic is free but Cross Region Replication is paid.
- Each Replica can be promoted to main DB
- Read Replica support only SELECT (Read)
- Add new endpoints with their own
DNS name. - Need to change application to reference new DNS individually to balance the read load.
- Use Case: Run Analytics, Reporting on Read Replica
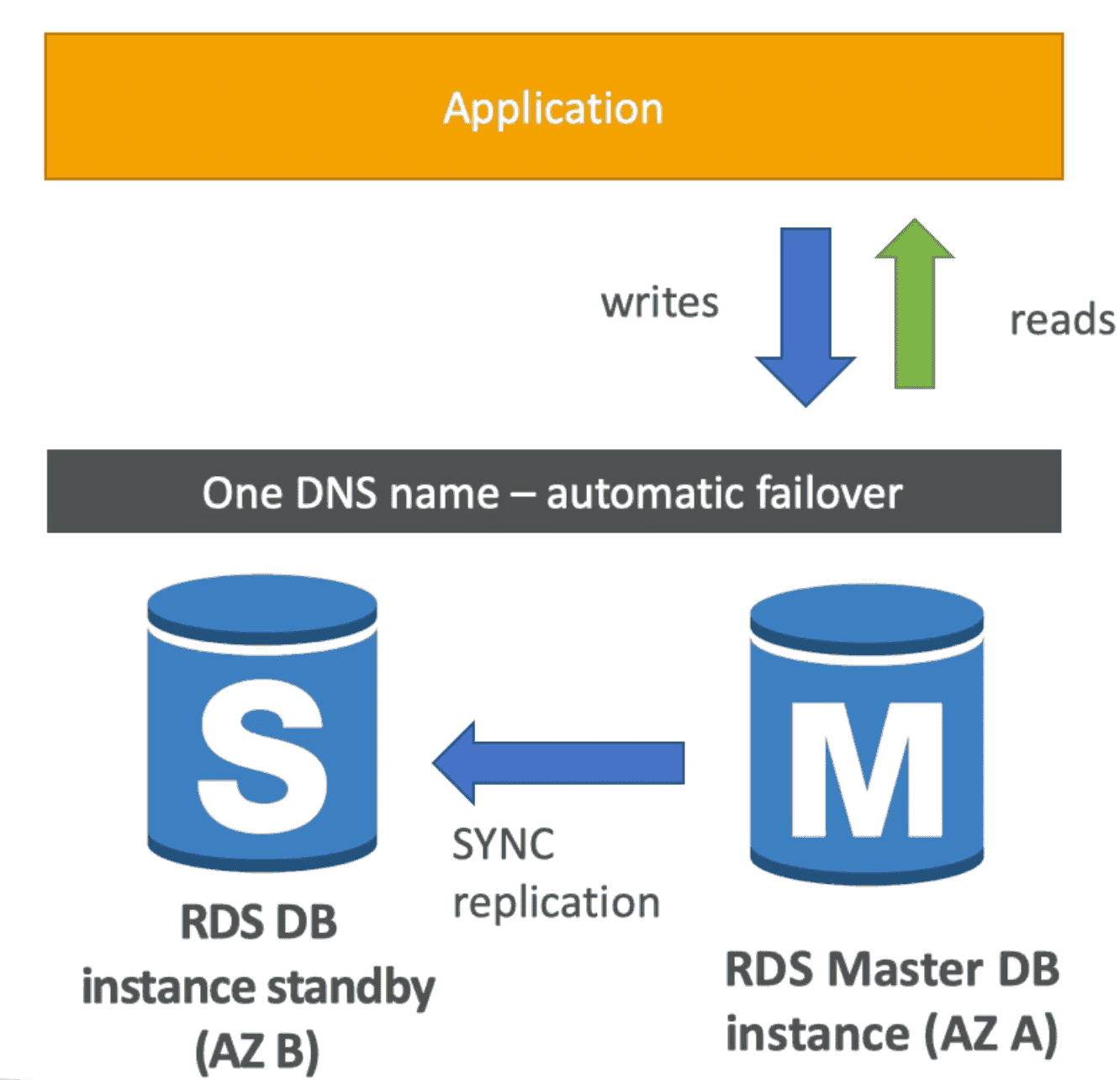
Multi AZ
SynchronousReplication of DB for Disaster Recovery
- Increase Availability by automatic failover
- Support Multi AVZ
- Standby Database promoted to main DB in case of Disaster
- StandbyDB does not support any Read/Write
- Keeps the same connection string regardless of which database is up. When used does not require to change the SQL connection string
Encryption
Master & Read Replica can be encrypted using AWS KMS AES256
- Encryption must be enabled while creating master DB
- Snapshot of Encrypted RDS is Encrypted
- Snapshot of Un-encrypted RDS is un-encrypted
- Un-encrypted RDS can be encrypted: DB => snapshot =>copy snapshot as encrypted => restore DB from snapshot
- Oracle & SQL Server can be encrypted using Transparent Data Encryption (TDE)
- In Flight Encryption supported using SSL
- Force SSL using
- PostgreSQL: using Parameter Group:
rds.force_ssl=1 - MySQL: SQl Command:
GRANT USAGE ON *.* TO mysqluser'@'%' REQUIRE SSL;
- PostgreSQL: using Parameter Group:
Security
- Deploy DB in private VPC within Security Group. DB must not be internet facing
- Use IAM policy for Access Management
- IAM Authentication for
MySQL&PostgreSQL
Autoscaling
Scale automatically to meet demand of DB to meet unpredictable DB demand
- 10% storage left for more than 5 Minutes
- Set Maximum Storage Threshold to avoid scaling infinitely
Amazon ARORA:
Fast & cost effective RDBMS Built for cloud
- Backed by benefic of RDS but not in free tier
- Self heal corrupted data
- Support Cross Region Replication
- 6 Replica across 3 AZ
4/6needed for Write3/6needed for read
MySQL & PostgreSQLcompatible- Fast: 5X MySQL & 3X PostgreSQL
- Cost 20% more but more efficient
- Scale automatically in multiple of
10GB up to 128TB
Aurora cluster: one Primary DB instance with up to 15 Read Only replicas.
- Failover happen over 30 Second with help of 15 Replicas
Writer End Point
Connect to main DB for Write Operation
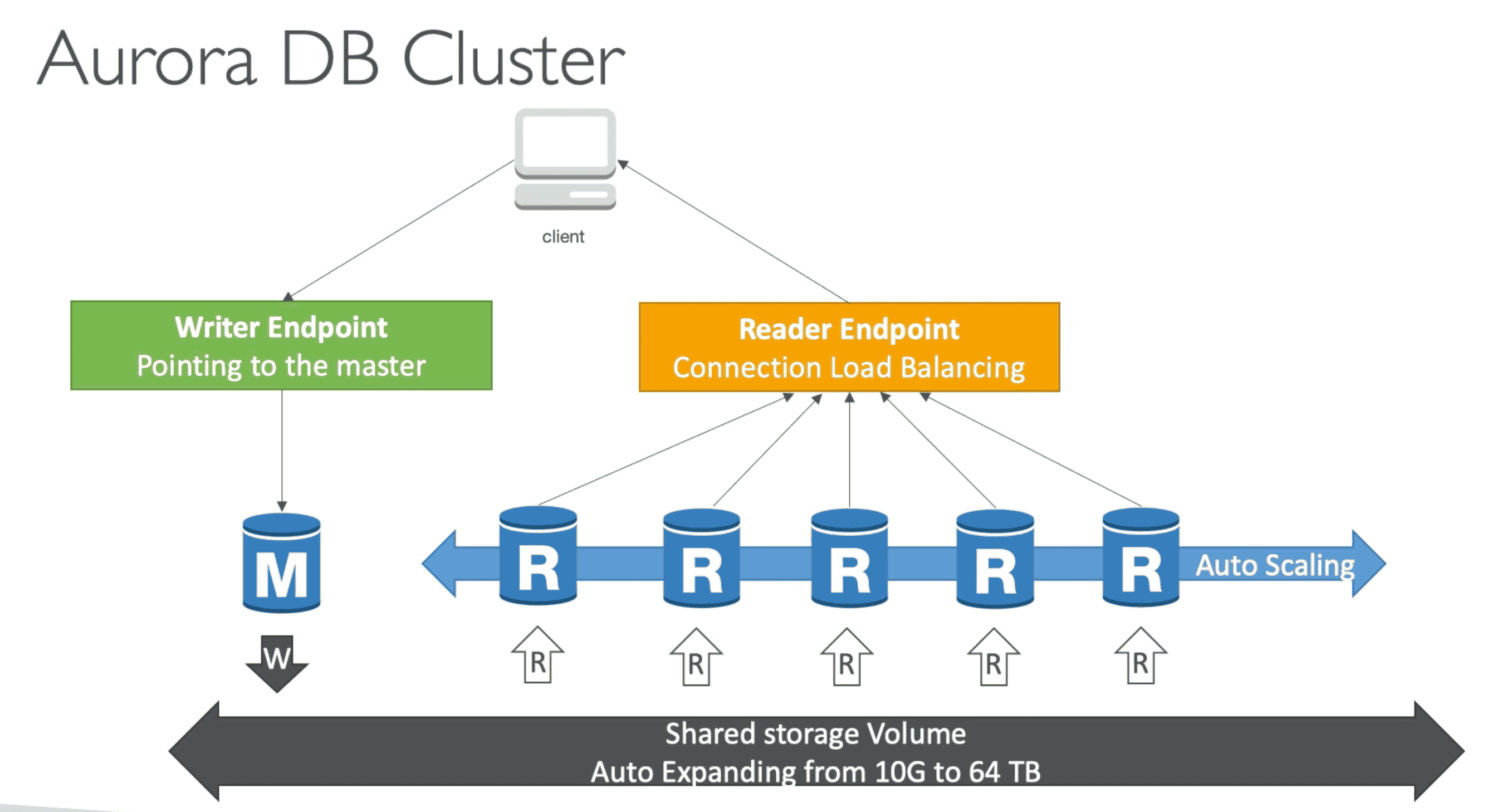
Reader End Point:
Connect to read replica for Connection load Balancing
- Reader endpoint automatically performs load-balancing among all the Aurora Replicas.
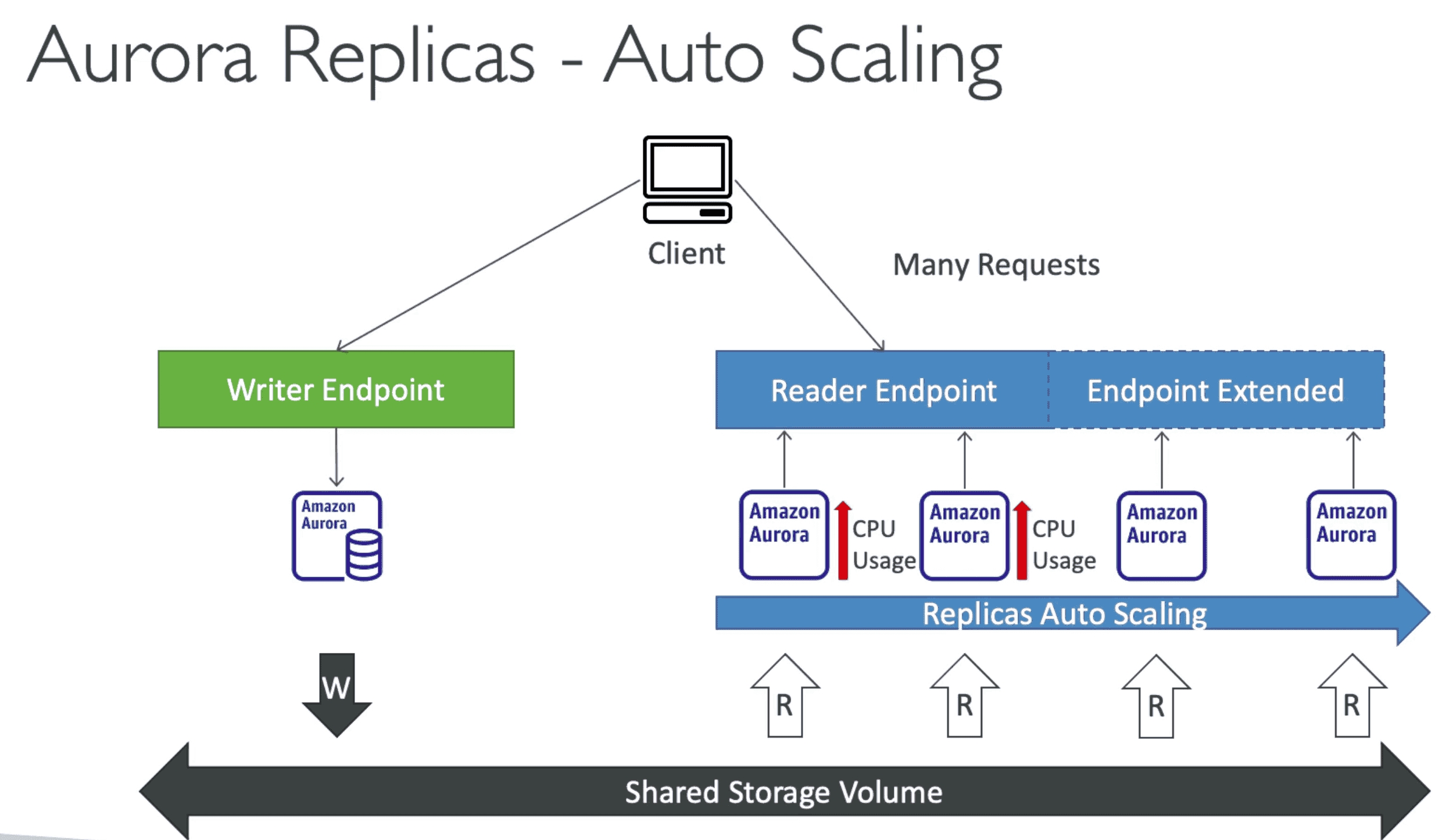
- Reader Endpoint can be custom defined:
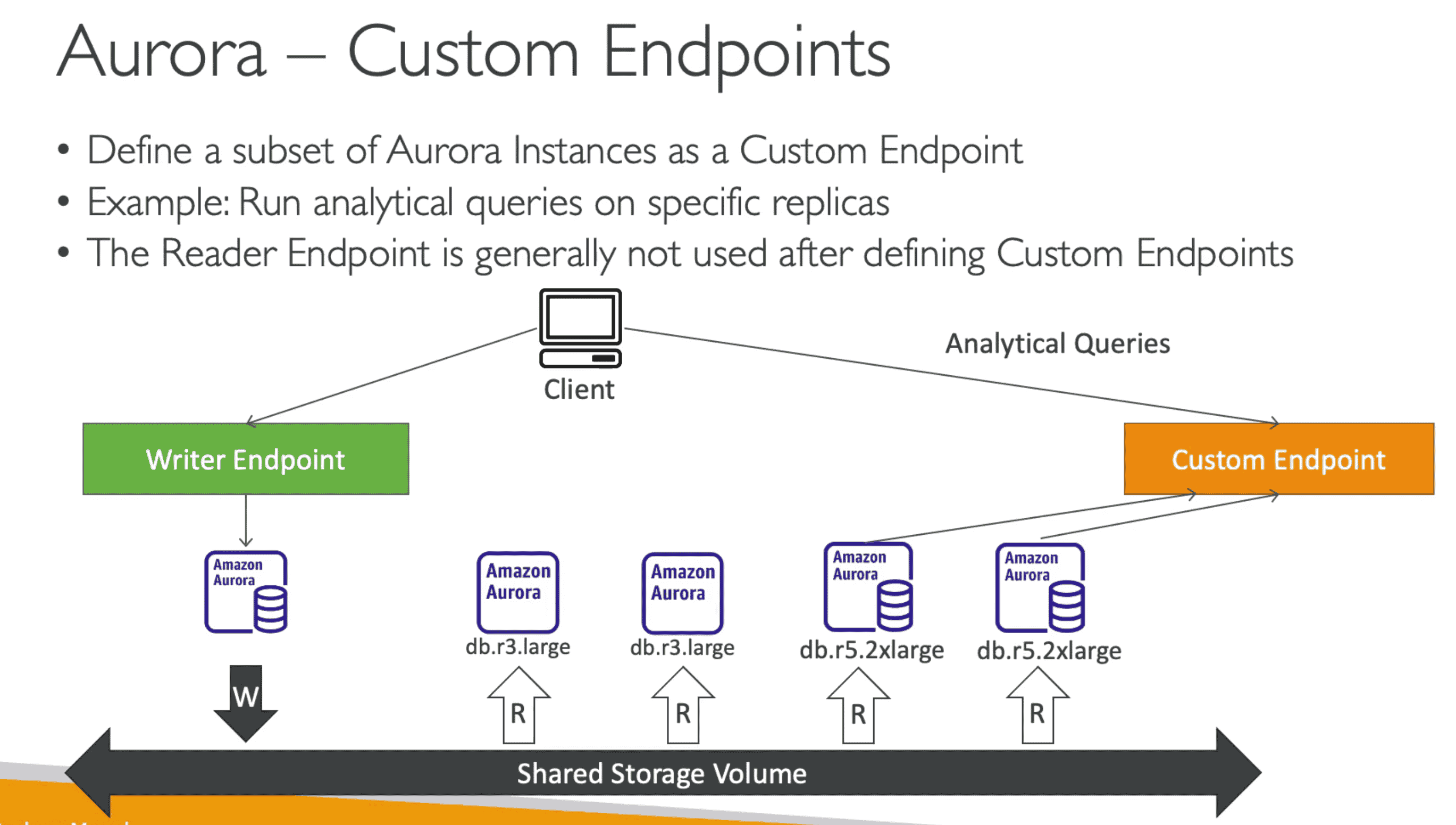
- DB instances in a multi-master cluster must be in the same AWS Region
- Can't enable cross-Region replicas from multi-master clusters.
Aurora Global Databases
allows you to have an Aurora Replica in another AWS Region, with up to 5 secondary regions.
Security
- Encryption ast rest using KMS
- Encryption in flight using SSL
- Authentication using IAM
- Hide behind Security Group
NoSQL Database
1. Amazon DYNAMO DB
Serverless Fully Manged Highly Available DB with Replication over 3 AVZ
NoSQLDB with key values pair- Single Digit Latency: MilliSecond Response Time
- High Performance: Automatic Scaling up to 10 Trillion request per day
- Integrated with IAM
- Low cost & Auto Scaling Capability
- Offers active-active cross-region support
- Multi AZ by default
- DynamoDB Lamda-> Stream all changes in DB
- backup & restore
- Can only be sort by primary key & index
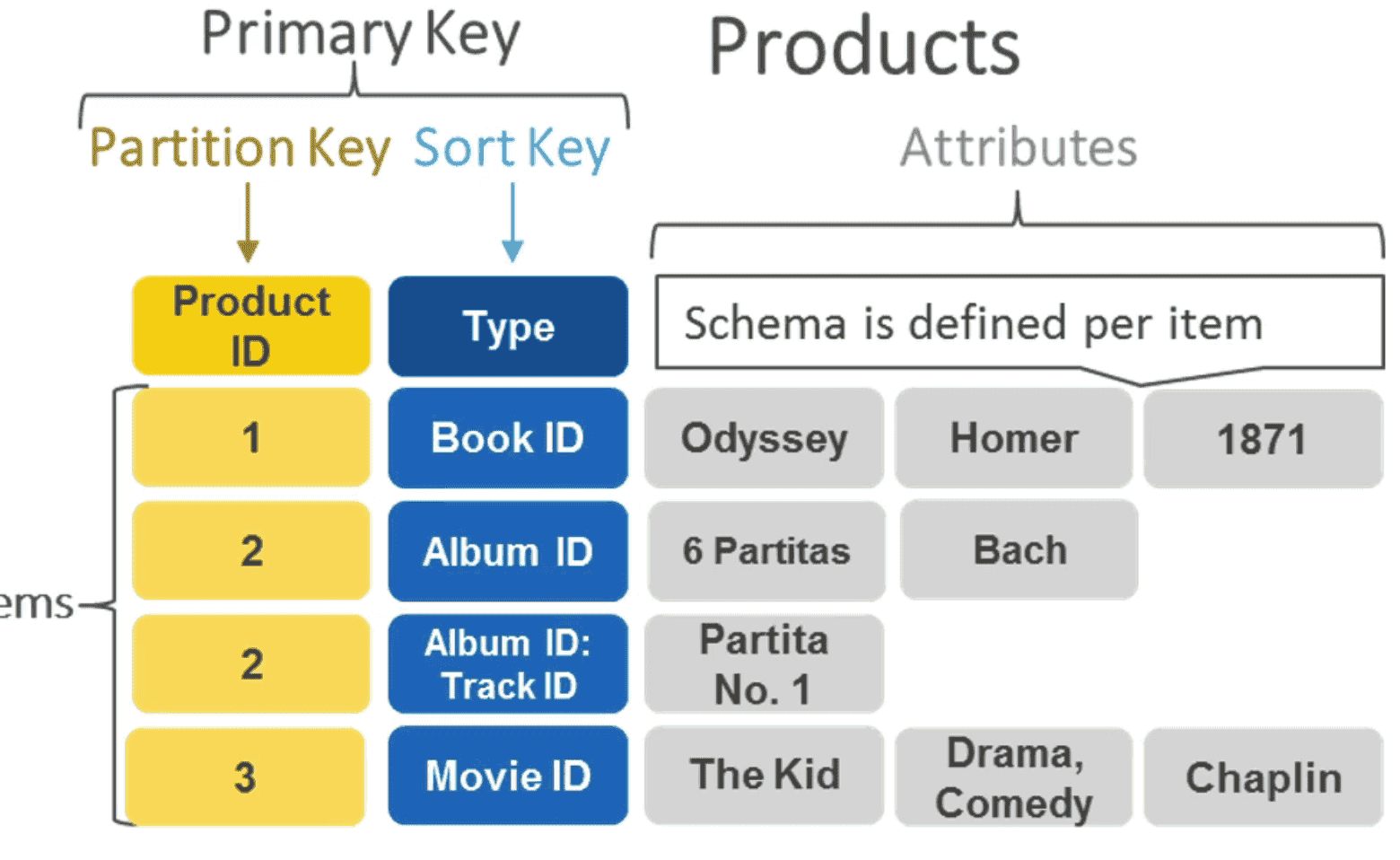
- Stored as item
<key,attributes>pair, where Key =Partition Key+Sort Key
Data Support
- Max Size
400KB - Scaler: Null, Binary, Boolean, String, Number
- Document Type: List , Map
- Set Type: Binary Set, String Set, Number Set
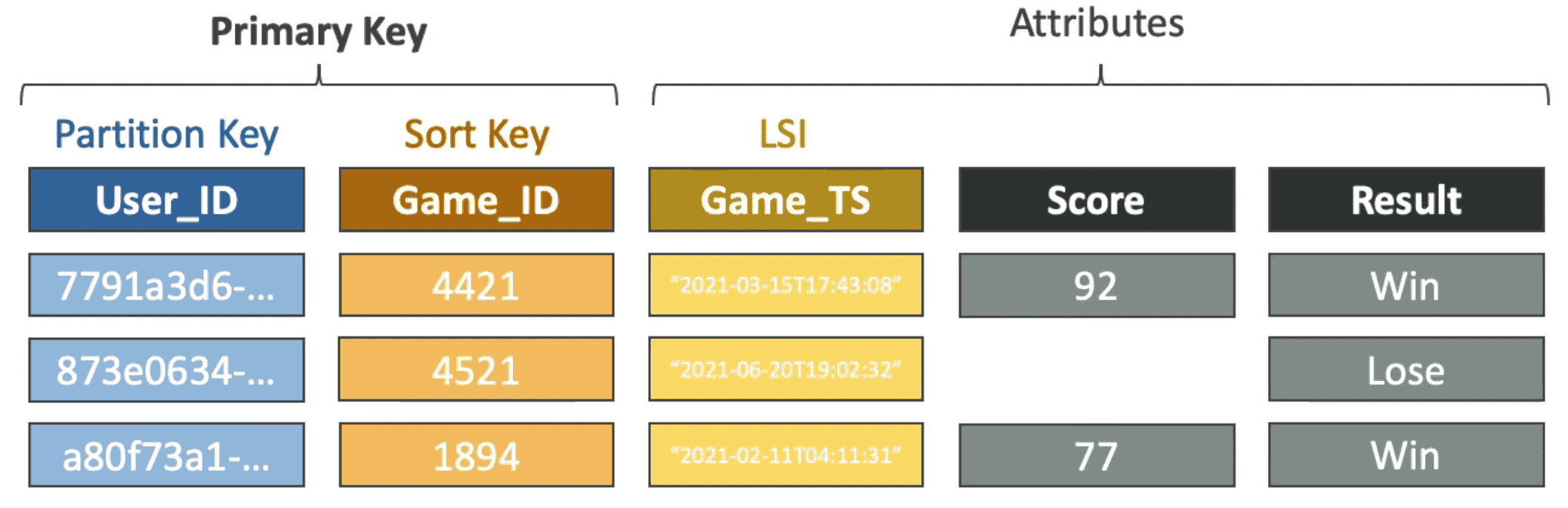
Local Secondary Index(LSI)
Alternative Sort key for Table along with partition Key
- Query to a DynamoDB table using an attribute that's NOT part of your table's Primary Key. You need to use the >= predicate while keeping the same Partition Key.
- Must defined on table creation
- Data: Boolean, String, Number
- Limit: 5/Table
- Can contain one or more Attributes
- UseCase: Server side filtering of data based on Attributes
- Throttling Throttling of LSI DOES NOT Throttles MainTable
- Uses same R/WCU as main Table
Global Secondary Index(GSI)
Alternate Primary Key :HASH Key, Partition Key, Sort Key
- Query to a DynamoDB table using an attribute that's NOT part of your table's Primary Key. What should you do to make this query efficient?
- Speed up queries on non key Attribute which can only be sort at Client side
- Create a secondary table with Attribute/s as Index as Table
- Data: Boolean, String, Number
- Need to provisioned WCu & RCU for new Table
- Throttling Throttling of GSI Throttles MainTable
- Must provisioned R/WCU of GSI in advance carefully to not Bottleneck the MainTable

Capacity Units
RCU & WCU are Spread Evenly Across Partition of DB
- A Hash code is generated using partition key to figure out partition for a Record
1. Write Capacity Unit(WCU):
Write/Sec for
1KBof Data
WCU = NumberOfItems* Math.round(WriteSize in KB/1KB)
- 6 item/Sec of 4.5KB = 6*5 = 30WCU <-- Round up 4.5KB to 5KB
- 10 item/Sec of 2KB = 10*2 = 20WCU
- 120 item/Min of 2KB = (120/60)*2 = 4WCU
Write Modes
- Standard(Default)
Some Write may Fail in some table
- Transactional
Write works across all Table or none of them works
Write Types
- Concurrent Write: Update Data At same time result in data overwrite
- Conditional Write: Conditional Update data
- Atomic Write: Both works
- Batch Write: Update multiple values at same time
2. Read Capacity Unit(RCU):
1 Read/Sec for Strongly Consistent Read of 2 Read/Sec for for Eventually Consistent for Data
4KB
Read Modes
- Eventually Consistent Read(Default)
Get
Staledata for read right after write in distributed read replicas - Strongly Consistent Read
Get latest data for read right after write in distributed read replicas
ConsistentReadParameter must be set true in: GetItem, Query, San, BatchGetItem- Consume 2 RCU/Read.
- Higher latency & costly
- Transactional
Read data from multiple Table and get Transactional View
RCU_Consistent = NumberOfItems* Math.round(ReadSize in KB/ 4KB )
RCU_EventuallyConsistent = (NumberOfItems/2)* Math.round(ReadSize in KB/ 4KB )
- 10 item/Sec SC of 4KB = 10*(4/4) = 10*1 = 10RCU
- 16 item/Sec EC of 16KB = (16/2)(16/4) = 84 = 32RCU
- 10 item/Sec SC of 6KB = (10)*(8/4)= 20RCU <-- Round up 6 KB to 8KB
Read/Write Capacity Mode
Control Table Capacity
1. Provisioned Mode(Default)
- Need to think beforehand capacity & R/W per Second
- Pay for provisioned R/W Capacity Unit
- Autoscaling can be enabled to increase capacity
- Cost can be estimated.
Burst Capacity: Temporary increase Throughput when RCU/WCU exceed provisioned capacity
ProvisionedThroughputExceedException: When R/WCU exceed provisioned Capacity
- Reason:
- Hot Partition: Same Partition is used frequently
- Hot Key
- Very Large Item
- Solutions
- Exponential Back off
- Distributed Partition Key
- Use Dynamo DB Accelerator to reduce read load
2. On-Demand Mode
- No capacity planning
- For unpredictable load Scale Automatically
- Unlimited R/W-CU but 2-3X expansive
- Pay for what you use in term of Read Request Unit(RRU) & Write Request unit(WRU)
- UseCase:unknown workload, unpredictable workload
Dynamo DB API:
WRITE
| API | Usage |
|---|---|
PutItem |
Put or Fully Replace item |
UpdateItem |
Update or Edit item Attributes |
Conditional Write |
Write/Update/Delete if condition met or send Error |
| READ |
| API | Usage |
|---|---|
GetItem |
Read 1 Item for primary key(HASH or HASH+RANGE). Supports both Strongly Consistent or Eventually Consistent Mode |
ProjectionExpression |
Return only certain Attributes |
Query |
Return Items based Key with Limit(no of item) or 1MB data |
KeyConditionExpression |
Query based on Partition Key with = Operator or SortKey with (=,<.<=>,>=, BeginsWith, Between) |
FilterExpression |
Additional filter after Query before data is returned on NonKey Attribute |
Scan |
Return entire table upto 1MB Data. Consumes Lots of RCU. Use LIMIT to limit number of data. Use Parallel Scan to increase throughput. Can pair with both FilterExpression & ProjectionExpression |
DELETE
| API | Usage |
|---|---|
DeleteItem |
Delete item with optional conditions |
DeleteTable |
Drop Table |
BathOperation |
Parallel Low Latency Operation on Multiple items. A part of batch can fail |
BatchWriteItem |
Upto 25 PutItem and DeleteItem per call: 16MB(400KB/item) |
BatchGetItem |
Upto 100 GetItem: 16MB in Parallel Call from 1 or more DB at a time |
Dynamo DB CLI
--projection-expression: subset of attribute--filter expression: filter data before return--page-size: return subset of data (default 1000)--max-items: max number of item to show in CLI(return NextToken)--starting-token: retrieve next set of item starting form last NextToken
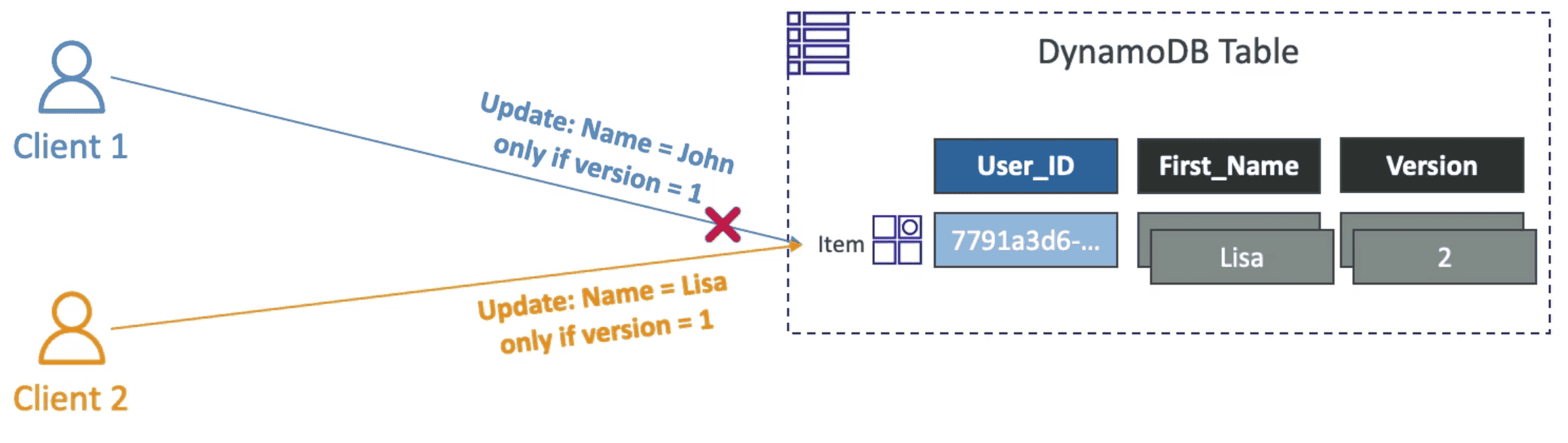
Dynamo DB Optimistic Locking
Optimize WRITE
Update/Deleteitem only if they are changed.
- Each item can have an Attribute with work as Version ID to avoid overwrite
Dynamo DB Stream
Ordered Stream of item level changes(create/update/delete) in DB table
- List of all changes over time in DynamoDB
- Retain for
24 Hour - Made of
Shardsprovisioned by AWS - Retroactive: Only new modifications are shown as Stream.
- Can choose information written to Stream
KEYS_ONLY: Attributes of Modified itemNEW_IMAGE: Entire item after changesOLD_IMAGE: Entire Item before changesNEW_AND_OLD_IMAGE: Both new & old Item Images
Use Case:
- Kinesis Data Stream: for persisting Data
- Lambda: Invoked Synchronously: Must have IAM permissions to poll from dynamoDb stream using Event Source Mapping
- Kinesis Client Lib
- Elastic Search: Indexing
- Email for data processing
- Global Table
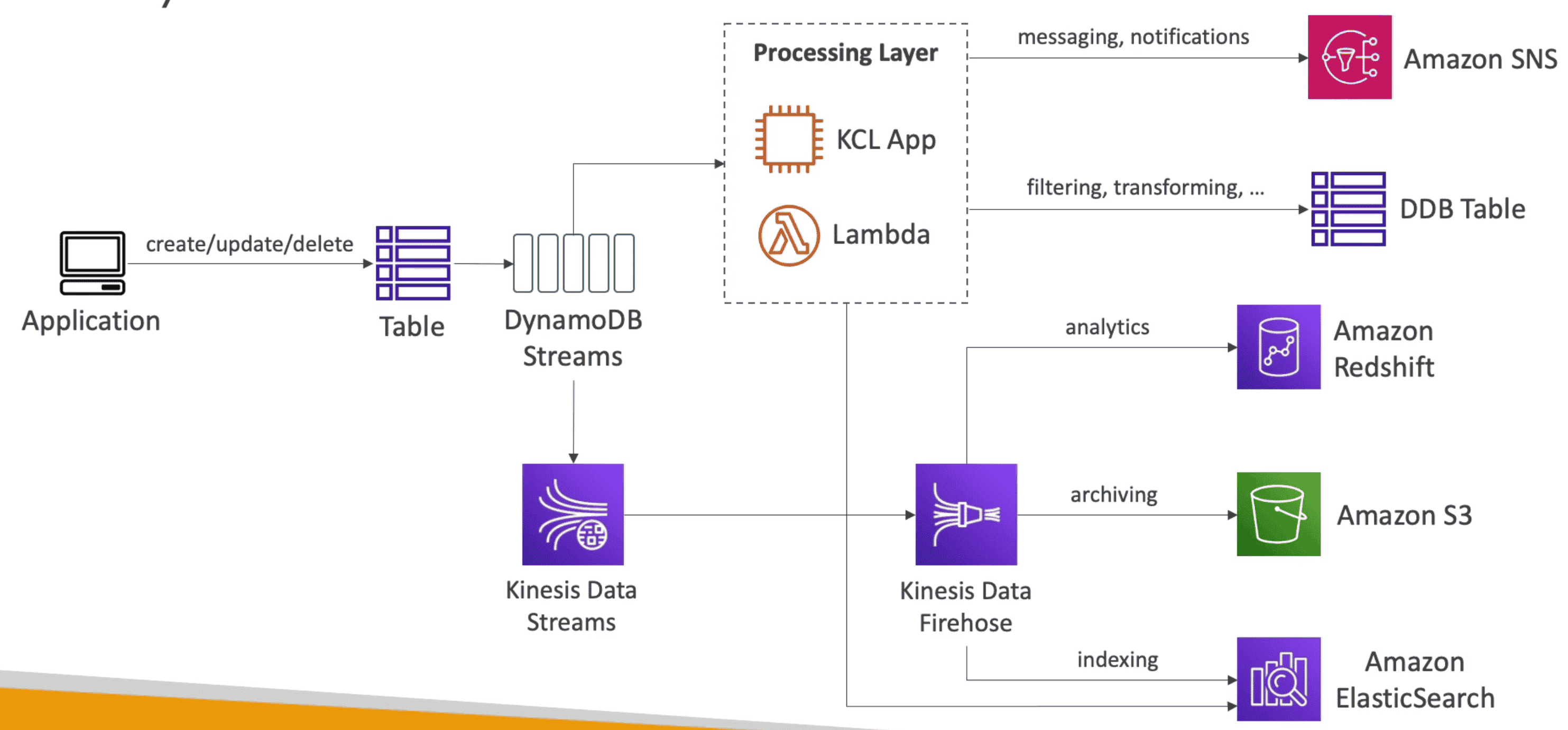
Dynamo DB Global Table:
Active/ Active Replication of Data Table in Multiple region to provide Low Latency
- Replicate DB in
multiple regionto make Data Accessible across multiple region at low latency - User can Read/Write from/to table close to them
- Must have Dynamo DB stream enabled to allow replication
Dynamo DB Local Table:
Offline Local DB for testing
Clean Up
- Scan + Delete-> Costly & Slow
- Drop & Recreate Table-> Fast & More efficient
Copy/ BackUp
- Data Pipeline--> External AWS Service using EMR to copy data
- Backup & Restore DB: No additional service require
- Scan+ BatchWrite--> Slow & Costly
Security
- IAM: Access Control
- VPC: Hide behind private VPC or use VPC End Point
- KMS: encryption at rest
- IdentityFederation: Temporary access using AWS Cognito to Modify own data
- Leading Key: Access management for user at low level
Dynamo DB Transaction
Coordinated One All or Nothing Transaction to add/update/delete to multiple Table or none of them )
-
Provide: Atomicity, Consistency,Isolation, Durability(ACID)
-
ReadMode: Eventual Consistent, Strongly Consistent, Transactional
-
WriteMode: Standard, Transactional
-
Consume 2X R/WCU: Perform 2 Operation per item (prepare & commit)
WCU = WCU * 2 RCU = RCU * 2 -
API: upto 25 Item or 4MB of data
TransactGetItems: 1 or moreGetItemsper operationTransactWriteItems: 1 or morePutItem,DeleteItem,UpdateItemper operation
-
Use case: Banks, Orders, Games
![]()
Expiry Time (ExpTime)
Auto delete a items after time expired TTL
- Does not consume WCU
- TTL must be number as Unix Epoch Timestamp
- Deleted Within 48 Hours: Expired item might be shown in queries so must filter out client side
- Auto Delete item form GSI, LSI
- Deleted item can be recovered using Dynamo DB stream
- Use Case: Session Data, Regulation
Session Sate
| DynamoDB | ElastiCache | EFS |
|---|---|---|
| Serverless AutoScaling | In memory | Shared File System attache to EC2 |
| Key/Value | Key/Value | File System |
Amazon ElasticSearch (ES)/ OpenSearch
Search & Index any field or partial match in DB
- Used with Big Data or NoSQl DB
- Based on Elastic Search Project
- Run on Server (not serverless)
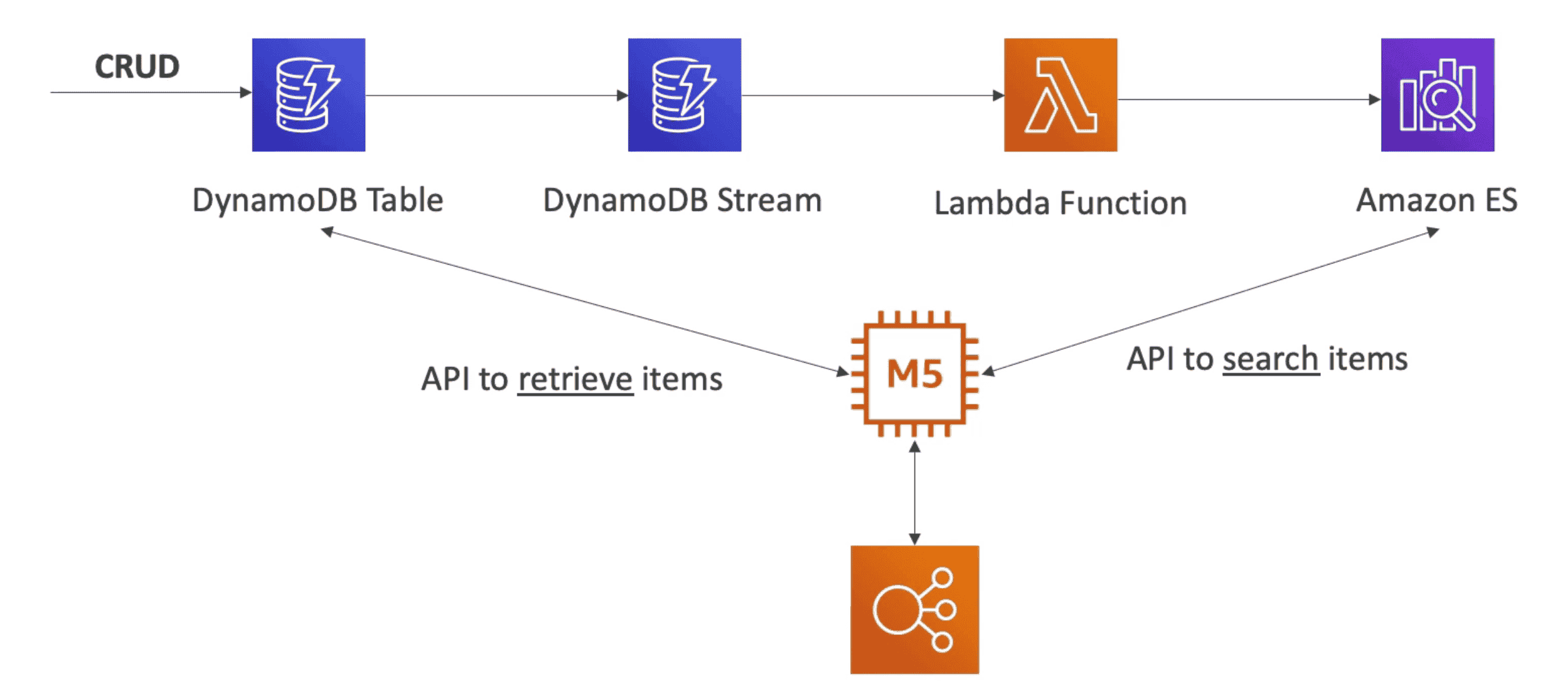
ES Access Policy
IP based policy to allow access to CIDR block of limited IPs
- Allow unsigned request using CURL, Kibana
- Private Subnet can access using SigV4
- Public CLient can Search via Proxy Server in public Subnet
Kibana does not support IAM Authentication
use following to authenticate access to ES
- SAML
- HTTP Basic AUthentication
- Cognito (using AD)
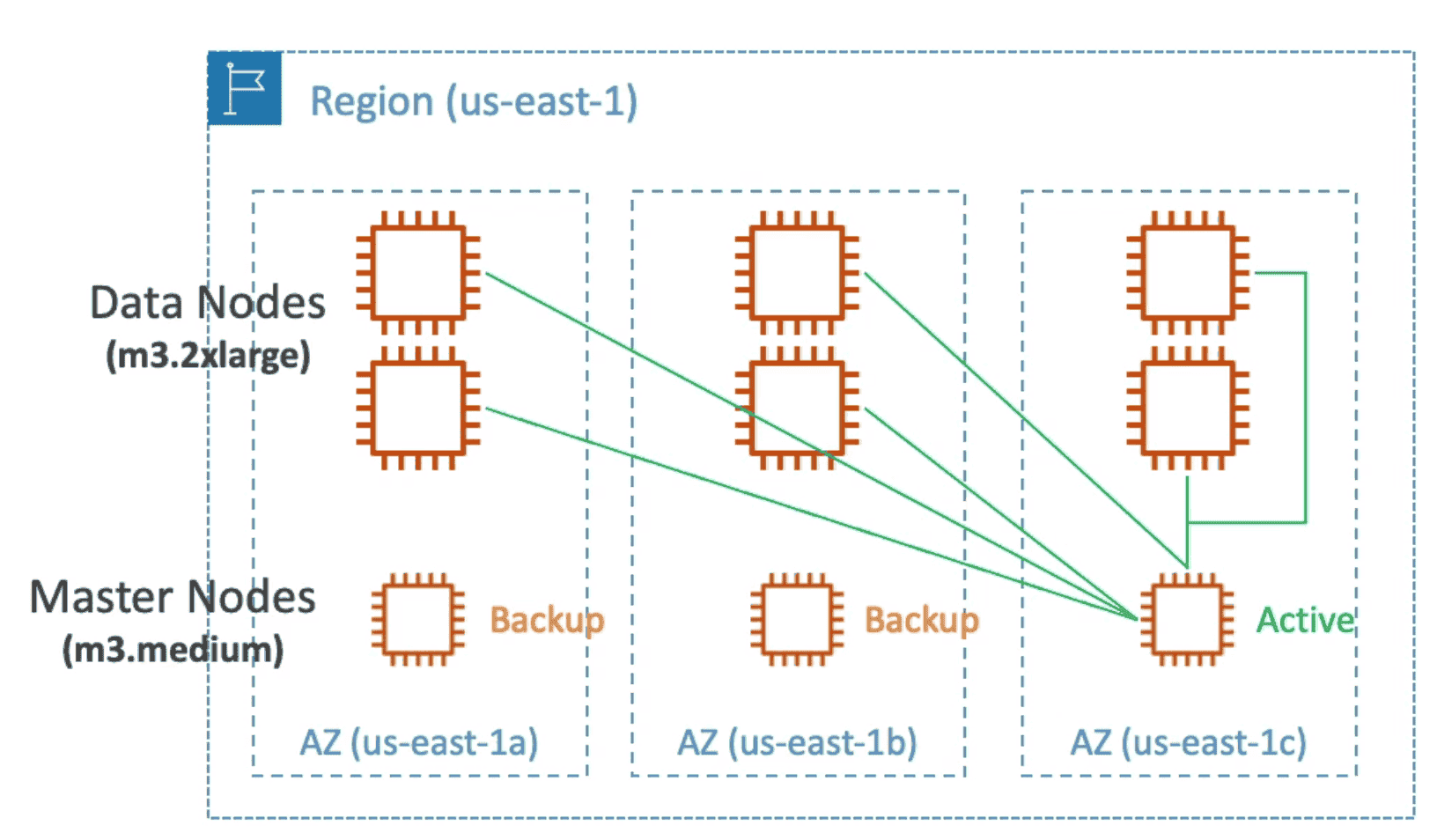
ES Production Setup
- VPC across 3 AVZ
- 3 Master Nodes: 1 per AVZ, 2 on standby 1 Active
- 6 Data Nodes: 2 per AVZ/Master Node. All connected with Active Master Node
2. Amazon DocumentDB:
MongoDB Database service
- Aurora Version for
MongoDB - Same features as Aurora
3. Amazon Neptune:
Graph database service.
- Highly available 3 AVZ & 15 Replica
- Can hold Billion of relation
- Point in Time Recovery, Multi AZ Clustering
InMemory Database
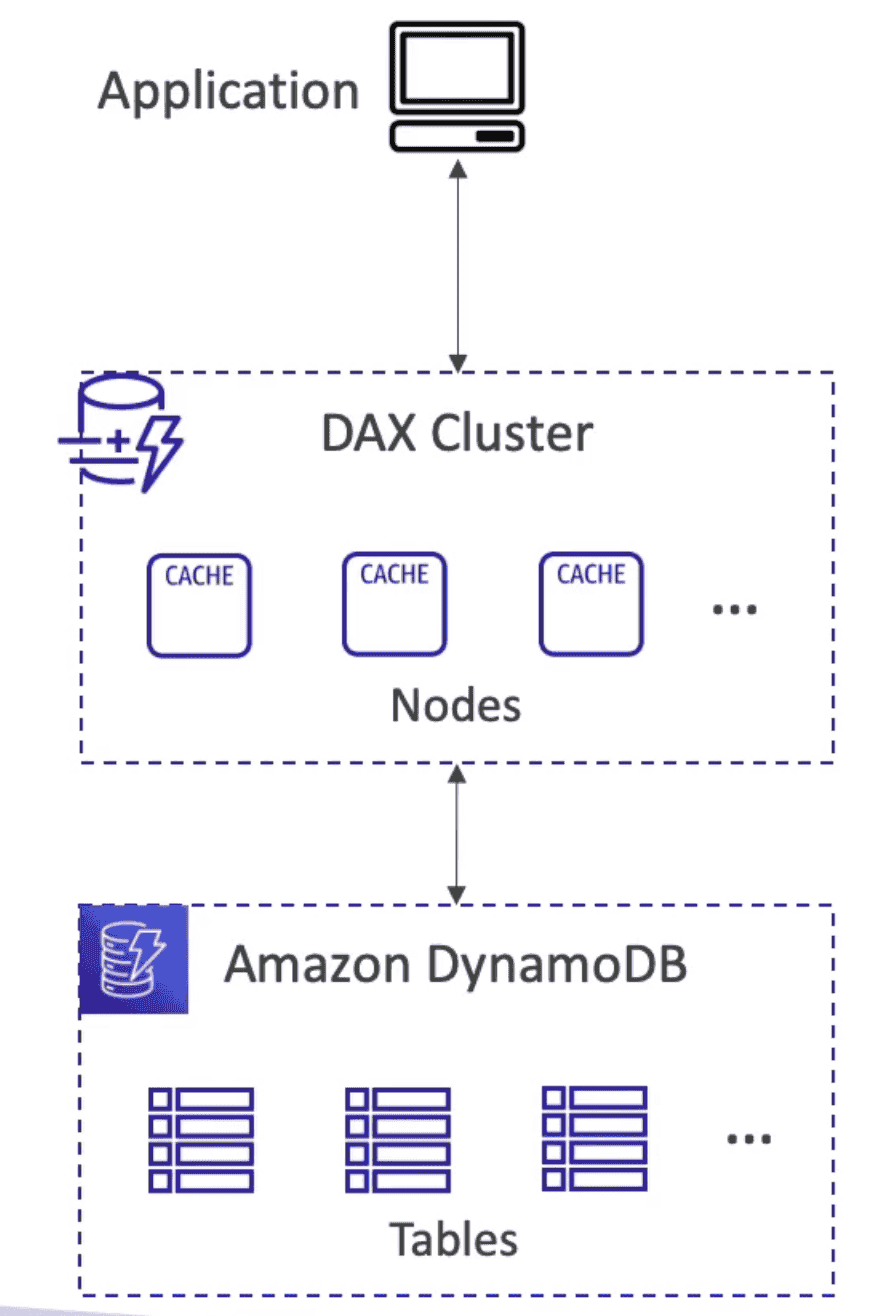
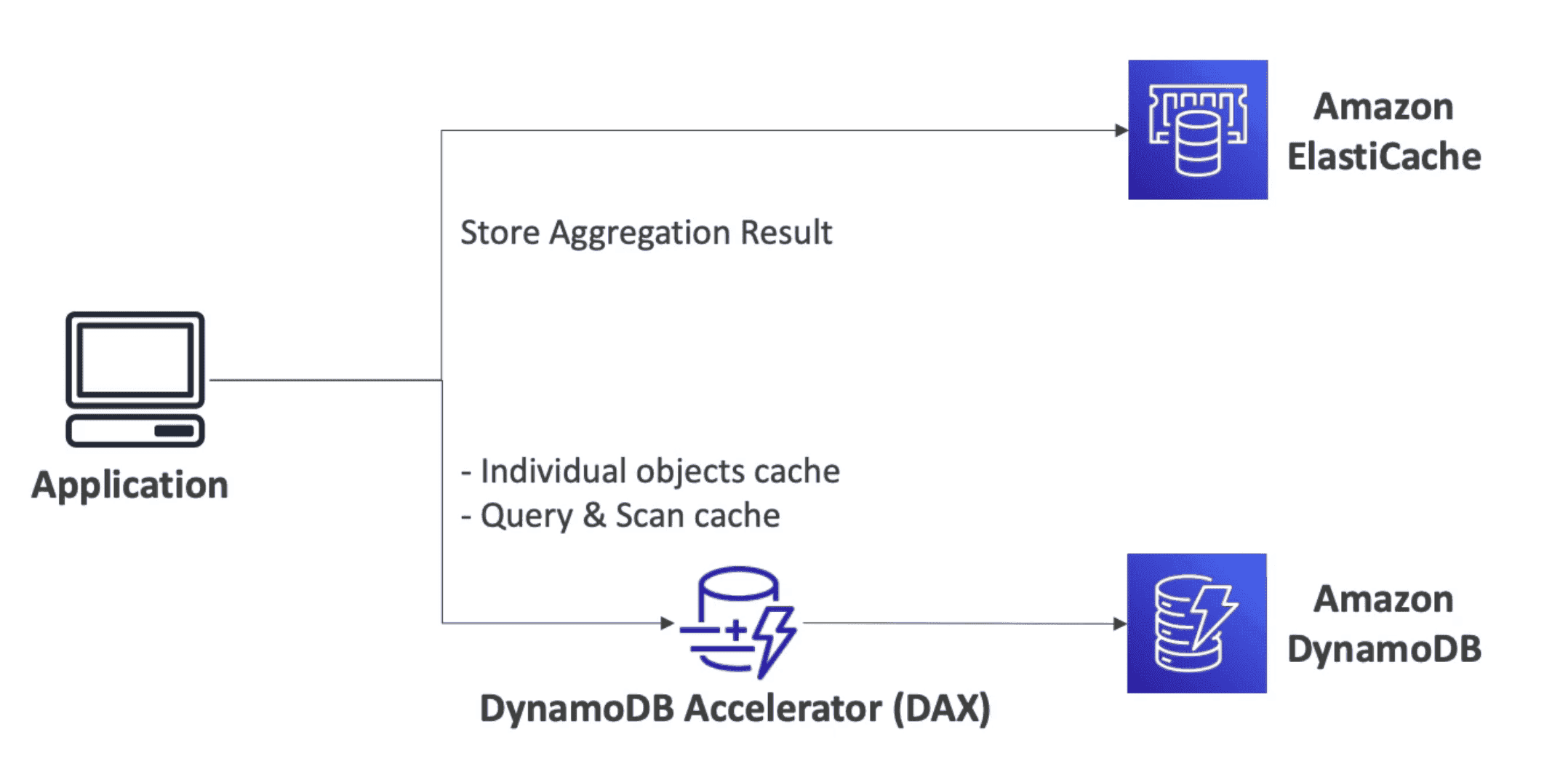
1. Amazon DynamoDB Accelerator (DAX):
Fully Manged in-memory cache used only for
DynamoDB.
- 10X performance with Dynamo DB
5 Minute TTLfor Cached Data- Upto
10 Nodesper Cluster. - Multi AZ: 3 Node /AVZ
- Does not need to modify app code as it only add a layer
- Micro Second Latency
- Highly Scalable & Available
- Does not offer active-active cross-Region configuration.
- Solve Problem of
HotKey: Reduce read of same data for a key above RCU - Support IAM authentication
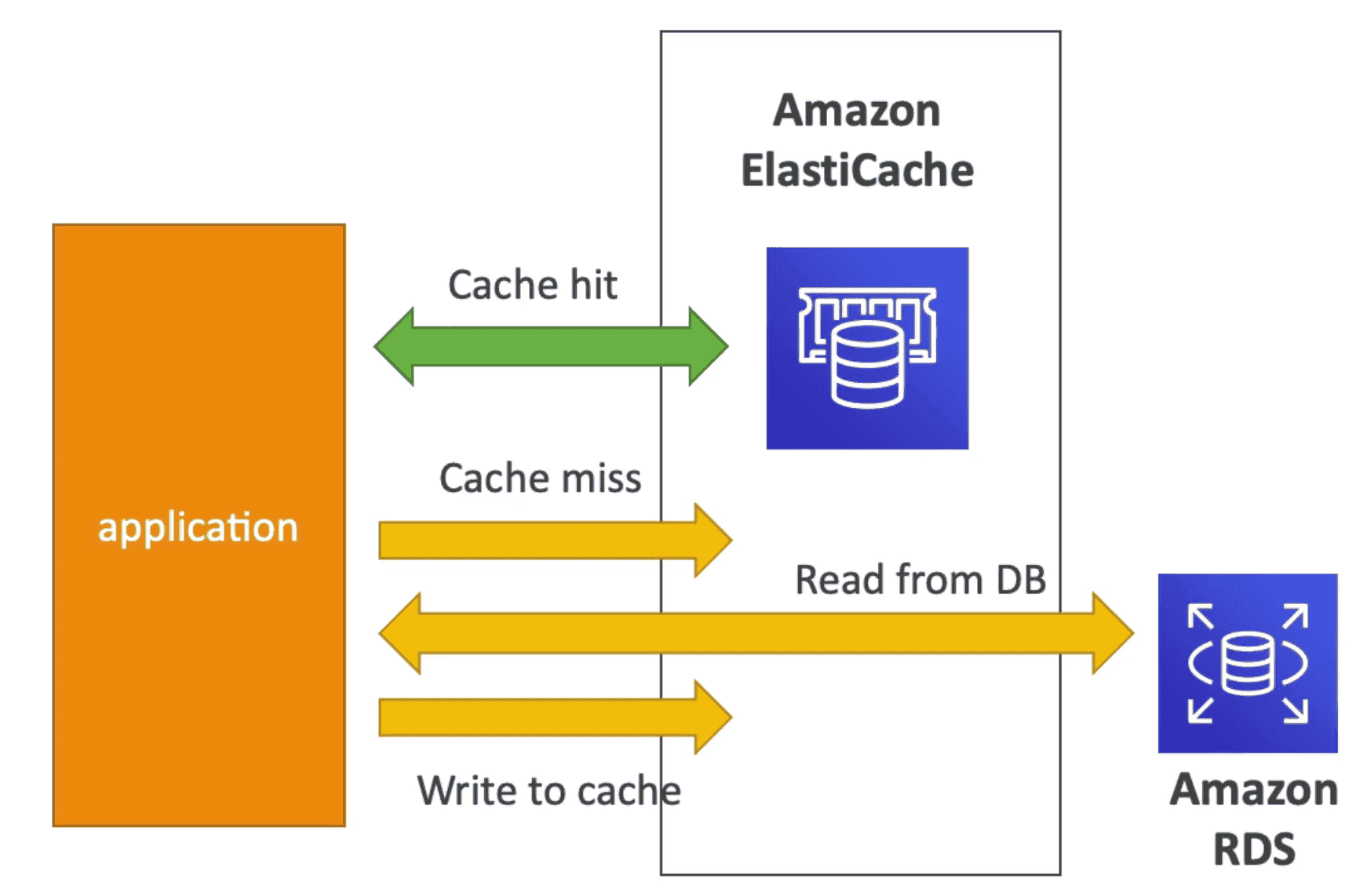
2. Amazon ElastiCache:
service to add caching layers to help improve the read times of common requests.
- In memory manged DB for All DB type
- Can be used along with DAX to store aggregated result
- Faster retrieve for common result
- Need to modify code a lot
- Support for Clustering in Redis to Multi AVZ
- Backup, Snapshot, point in time restore
- Monitor through Cloudwatch
- Pay per hour for EC2 type used & Storage used
- DO Not support IAM Bases Authentication
| REDIS | MEMCacheD |
|---|---|
| MultiAZ Auto Failover | Multi Node for Partition of Data(Sharding) |
Highly Available |
No High Availability |
| Backup & Restore | No Backup & Restore |
Data Durability |
Non persistent |
| Can also work as DB | High Performance Multi Threaded Distributed Cache |
Redis AUTH for Encryption on Rest |
SASL based Authentication |
| SSL for Encryption in Transit | |
| HIPAA compliant |
Caching pattern
- Lazy Loading: All Data is loaded when cache miss
- Write Through: Add to Cache when added/updated to DB
- Session: Store session data
Big DATA & Business Analytics/ Intelligence OLAP(Online Analytical Processing )
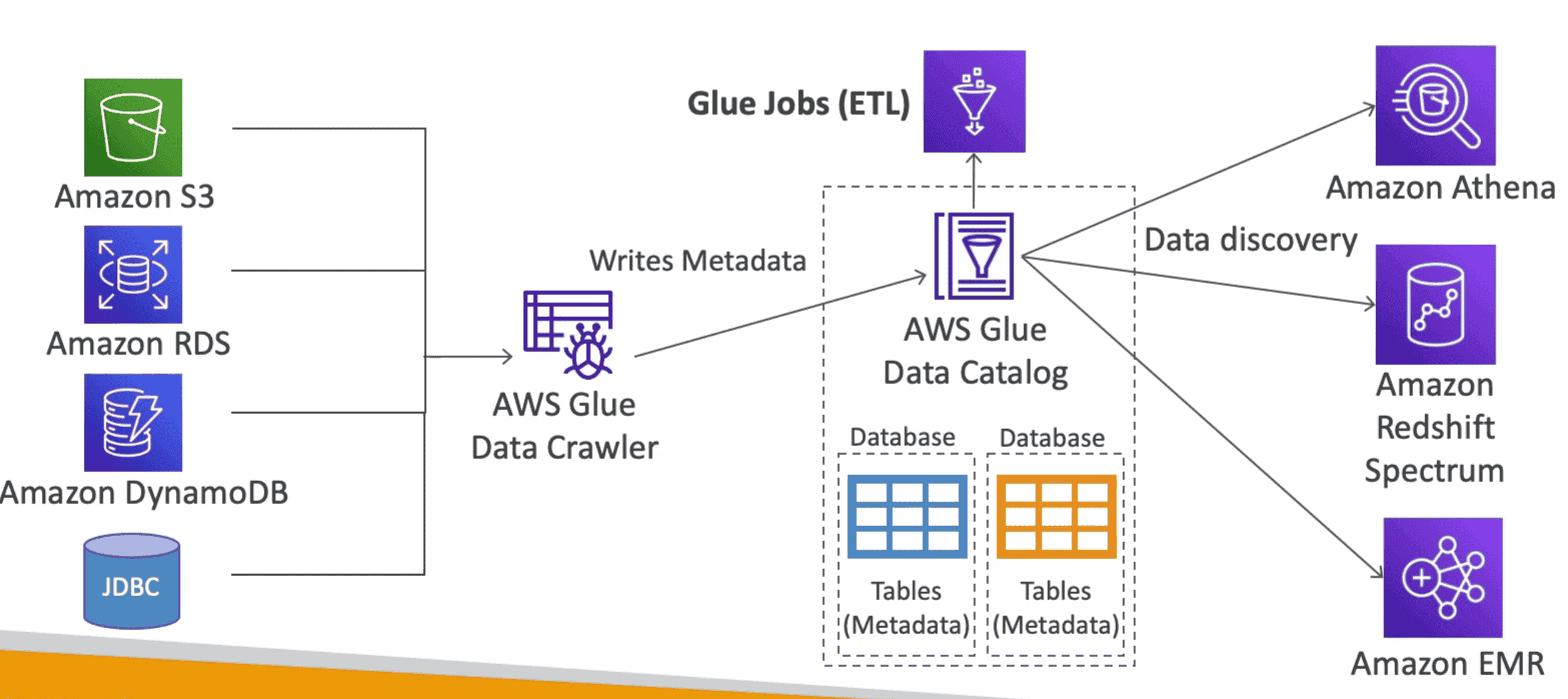
Amazon Glue
Manged Extract, Transform & Load (ETL) Service to transform data
- Serverless service to transform data for analytics
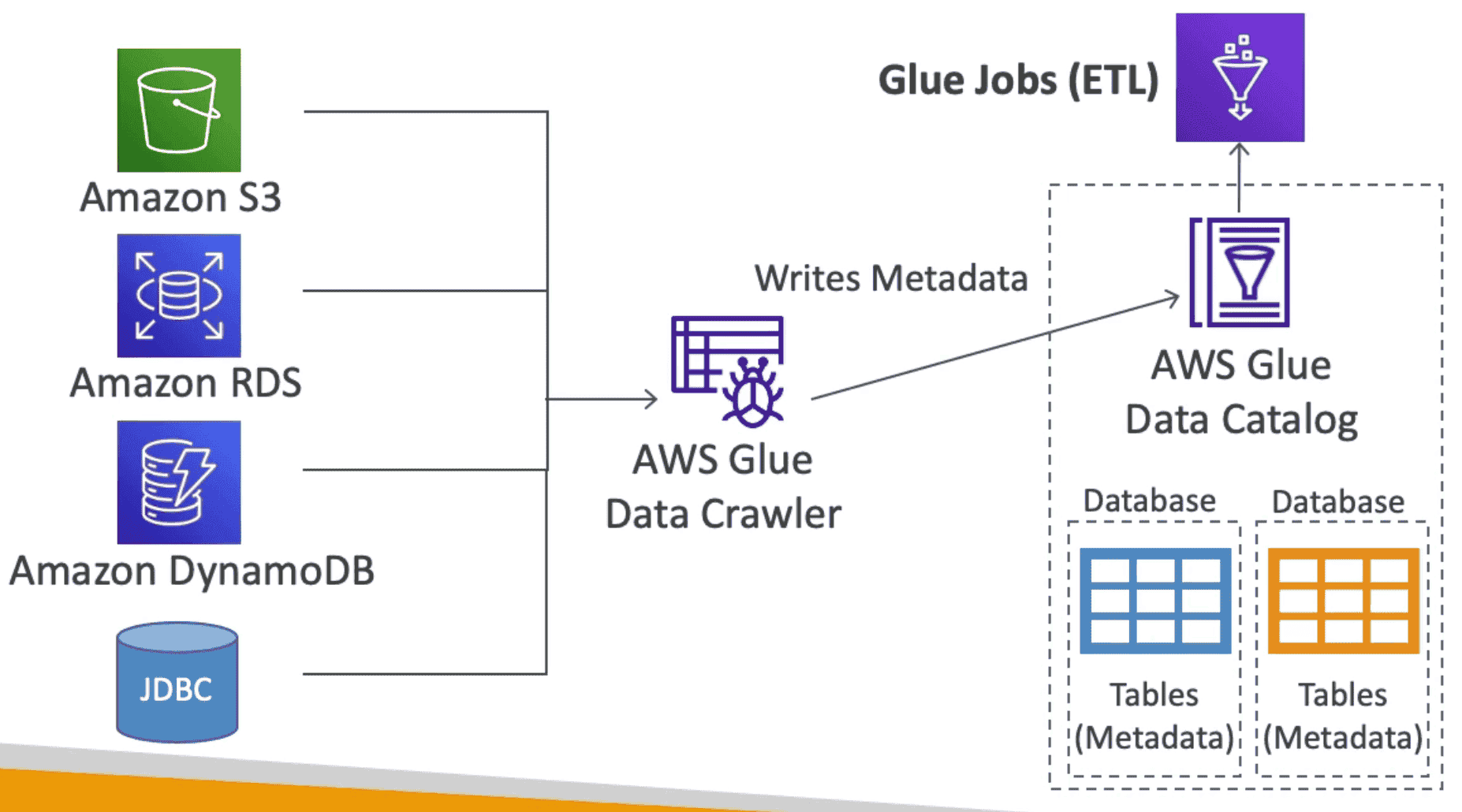
Glue Data Catalog
MetaData Catalog of DataSet created by Glue provide Column Info to Analytics Service
1. Amazon Red Shift
Data Analysis Service for Data Warehouse, OLAP
- Work well with Huge Volume & Variety of data
- 10X performance for Data Warehouse & Analytics
- Based on
PostgreSQL - Data is Store in Column
- Scale to PetaByte & Highly Available
- Load data every hour
- Massive parallel Query Execution (MPP) with SQL interface for query
- BI Tools integrated to create Dashboard
- Load from S3, Dynamo DB, DMS
- Support upto 125 Node with each node can handle 128 TB
- Node can be Leader Node & Query Node
- Redshift enhanced VPC Routing: COPY/UNLOAD go through S3 instead of Internet
- Multi-AZ deployments supported for RA3 clusters (since 2023); snapshots also allow restoring into other AZs/regions
Loading Data to Redshift:
- Amazon Kinesis FireHose: Put Data to S3 & Route Data to Cluster
- Route Data through Internet or enhanced VPC routing
- Use JDBC Connector
RedShift Spectrum:
Efficiently query and retrieve structured and semistructured data from files in Amazon S3 without having to load the data into Amazon Redshift tables.
2. Amazon Elastic Map Reduce (EMR)
Provision to Create Cluster of EC2 instance
- For Cluster Analysis of Big Data
- Can be used to create
- Hadoop Cluster for Big Data Analysis
- Apache Spark
- HBase, Presto, fling
- Autoscaling & spot instance
- Usage: BigData, ML, Indexing
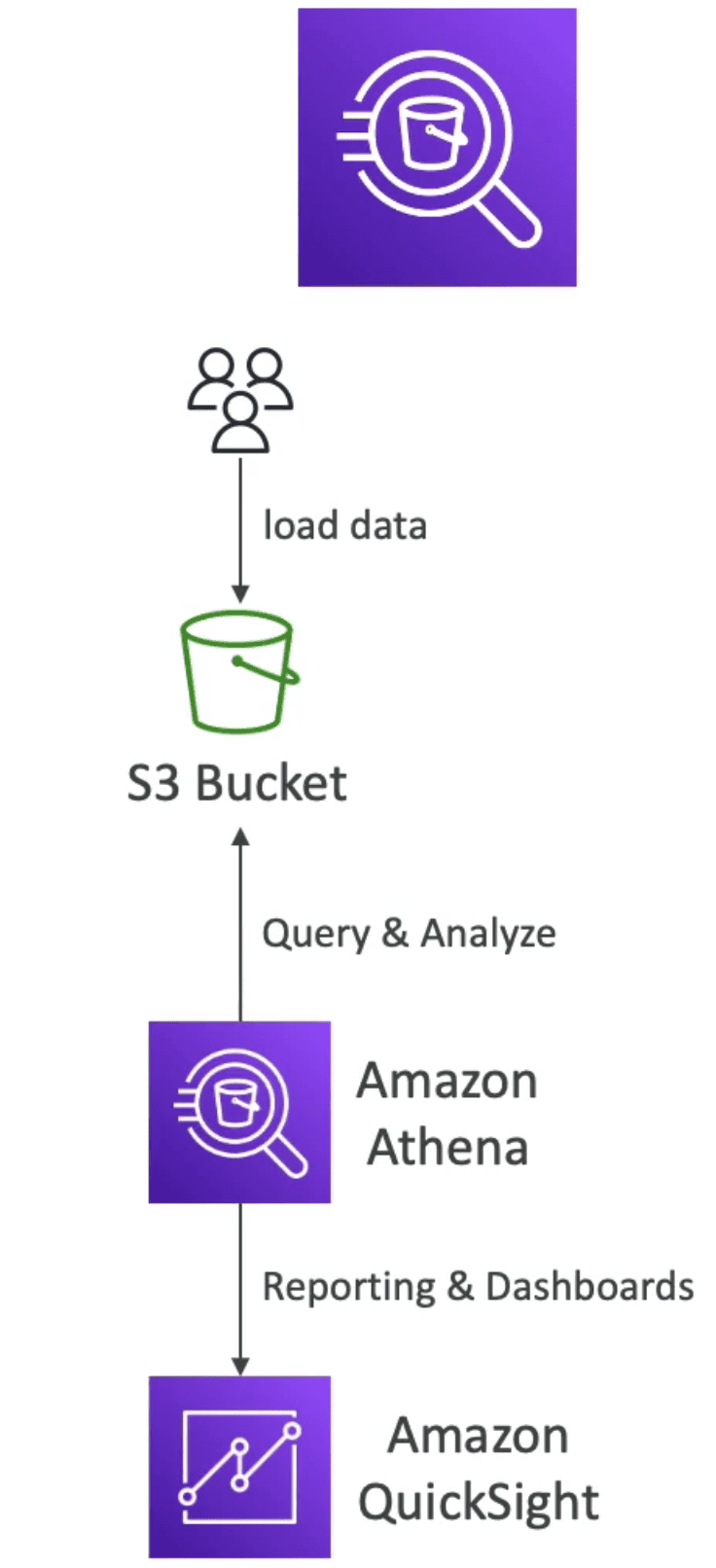
3. Amazon ATHENA
Serverless Query serviceto perform Analytics against S3 Objects
- Use
SQLto Query files inS3 - Work on top of CSV, JSON, ORC,Avro, Parquet
- Athena Query & Analyze the Data & create report on Amazon
QuickSight - Price: $5/TB Data scan
- Pay per query/ per TB of data scanned: compressed dta scan save cost
- Usage: Analytics, BI, reporting, Analysis, Flow Log,
QuickSights
Serverless ML powered Business Intelligence service to create Interactive Dashboards
- Give insights of data in cool dashboard
- Integrated on top of Aurora, Athena, Redshift, S3 ...
- Usage; Business Insights & Analytics, Visualization,
Ledger
1. Amazon (QLDB Quantum Ledger Database)
ledger database service. Review a complete history of all the changes that have been made to your application data.
- Central Manged DB
- Immutable: Write one Read many
- Fully Manged, serverless, highly available
- Hold Sequence of Modification using Crypt Hash
- 2-3x better performance than common ledger blockchain frameworks
- SQL Support
- Usage: Financial Transaction
2. Amazon Managed Blockchain:
service to create and manage blockchain networks with open-source frameworks. distributed ledger system
- DeCentralized DB
- Public Block chain network with support for Ethereum
AWS DB MIGRATION SERVICE(DMS)
Lift & Shift Migrate DB to EC2 securely & easily between Source & Target DB.
-
Source can remain operation to reduce down time
-
Support Multi AZ Migration
-
EC2 instance perform the data migration
-
Source:
- On Premises: Oracle,MS SQL Server, MySQL, Maria DB, PostgreSQL, MongoDB, DB2, SAP
- AWS:
RDS, S3 - Azure SQL Server
-
Target:
- On Premises: Oracle,MS SQL Server, MySQL, Maria DB, PostgreSQL, MongoDB, DB2, SAP
DynamoDB, RDS, Redshift, S3, ElasticSearch, Kinesis, Document DB
-
DMS supports specifying Amazon S3 as the source and streaming services like Kinesis and Amazon Managed Streaming of Kafka (Amazon MSK) as the target.
Schema Conversion Tool(SCT)
Convert Data base schema from one engine to another
- Source DB--> SCT +DMS --> Target DB
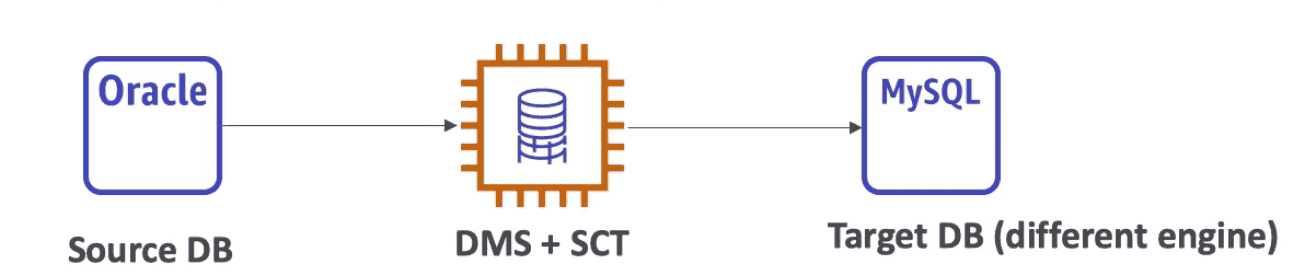
Support:
- Homogeneous Migration
between same & target type eg SQL to SQL
- Not need SCT
- Heterogeneous Migration
between different source & target type eg. SQL to noSQL.
- Need SCT
Use cases
- Develop & test DB Migration
- Consolidate: combine several DB into one DB
- Continuos Replication: ongoing copies
Pricing
- Pay for Instance
- Pay as Go
- Reserve Instance
- pay for Storage & IO
- Pay for data transfer between region
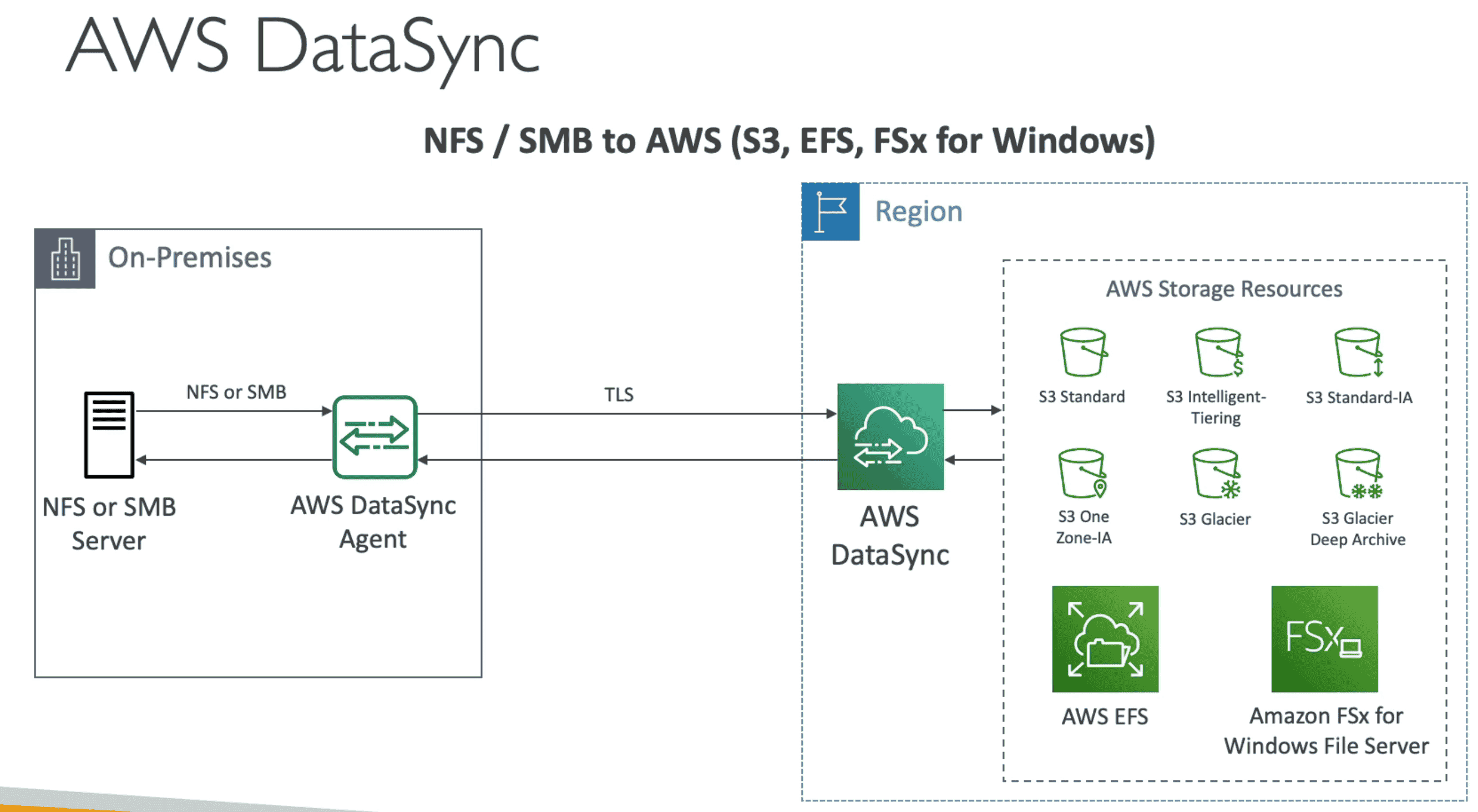
AWS DATA SYNC
Incremental Scheduled sync of large amount of data data from on premise server to
S3 (include Glacier), FSX for Windows, EFS
- Scheduled Replication: replication can be scheduled on regular interval hourly, weekly
- Use Data Sync Agent to connect to system on premises or EFS
- Move Data using
NFSorSMBprotocols - Can Sync EFS across regions
- Possible to set bandwidth to reduce network usage
- Copy un-encrypted EFS to encrypted EFS or move data across EFS
CopyObjectAPIs to copy objects between S3 buckets
AWS BACKUP
Fully manged Automate Backup process to backup resources in
S3cloud
Automate/manage cross-regions backups of AWS resources:
- EC2, Storage Gateway
- RDS, Aurora, DynamoDB,
- EFS, FSX, EBS
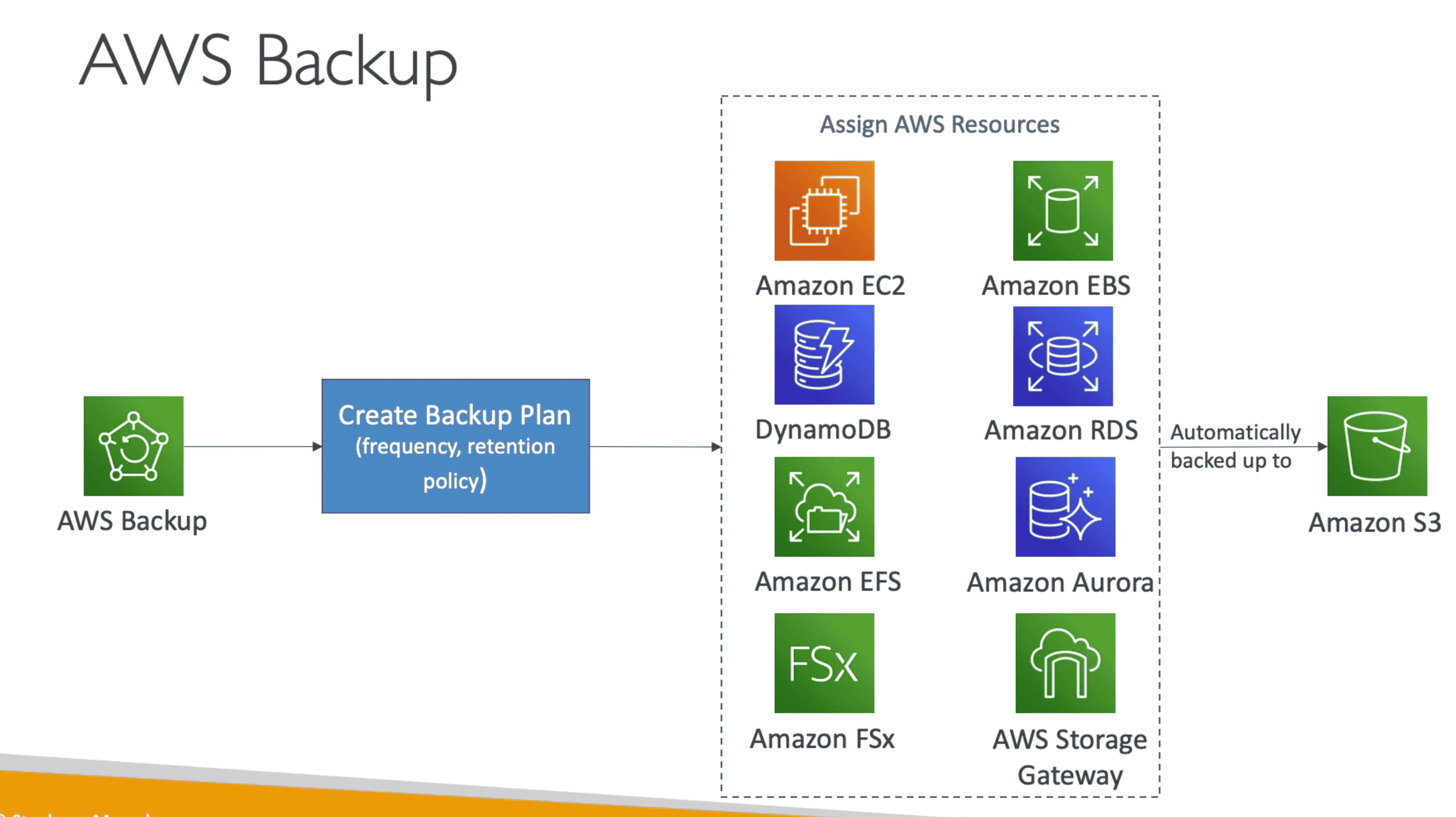
-
On demand or automatic scheduled backup based on
Backup Plan(policy)- Frequency: Can be Daily, weekly Monthly.
- Transition to cold storage
- Retention period
- Resource with tag can be added to backup plan
-
Support Cross Region/Account backup
-
Serverless: No need to create script to run backup
-
Support Point in Time recovery (PITR)
CLOUD ENDURE
Continuous replication of Data from corporate server to cloud
- Quickly migrate to cloud in case of business server fail