
Azure Database Services
Overview of available Azure DB Services: SQL, NoSQL, In-Memory, and NewSQL databases
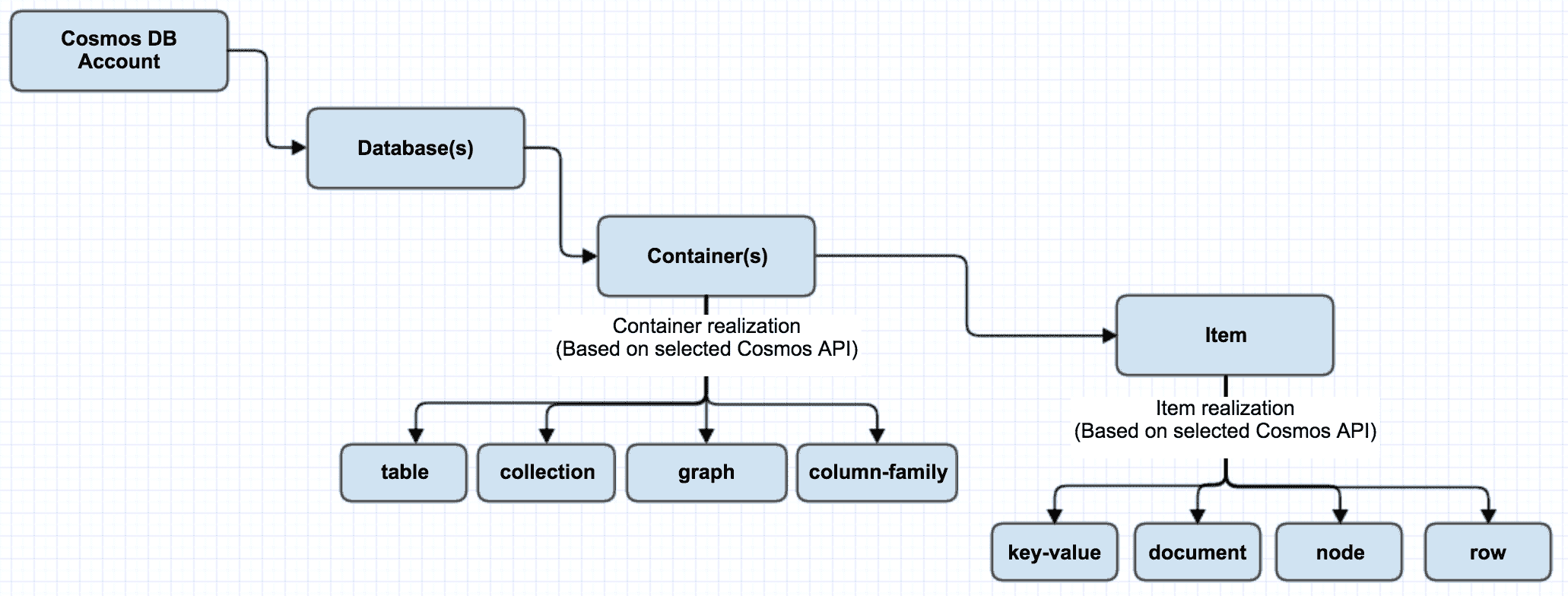
DATABASE
 |
|
NoSQL/ NonRelational DATABASE
Azure Cosmos DB
Fully managed
NoSQLdatabase to handle massive amounts of data, R/W at a global scale with near-real response times for a variety of data.
- Supports:
- SQL API (Core): Cosmos DB's own native API, queried with SQL-like syntax over JSON documents
- Cassandra API: only supports OLTP scenarios.
- Gremlin API: only supports OLTP scenarios.
- Table API: only supports OLTP scenarios.
- API for MongoDB: compatible with
MongoDB wire protocol, store Data in
BSONformat but does not use any native MongoDB API.
Features
-
Fast: Single-digit millisecond response times. Throughput and consistency all backed by SLA
-
Scalable: Independently and elastically scale storage and throughput across any Azure region with automatic and instant scalability guarantee speed at any scale.
-
Availability: 99.999% Read/Write availability all around the world.
-
Globally distributed: Multi-region writes and data distribution to any Azure region
-
Build highly responsive and "Always On" applications to support constantly changing data.
-
Serverless: Fully managed
NoSQLdatabase service. Automatic, no touch, maintenance, patching, and updates, saving developers time and money. -
Cost-effective: for unpredictable or sporadic workloads of any size or scale, start easily without having to plan or manage capacity.
-
Encryption at rest using
AES-256 -
Usage: IoT and telematics, retail and marketing, gaming and web and mobile applications.
Modes based on RU
System resources (CPU, IOPS, and memory) required to perform the Operation on DB
1. Provisioned throughput
Provision RUs/Sec in increments of
100 RUs/second.
- increase/decrease RU at run time by
100 RUsprogrammatically or fromAzure portal. - Provision throughput at container and database granularity level.
2. Serverless mode
Don't need to provision RU in advance. Billed for the amount of RU consumed
- Usage: Dev/Test environment with unpredictable load
3. Autoscale
Automatically and instantly scale based on usage.
- Usage: mission-critical workloads with unpredictable traffic patterns, and require SLAs on high performance and scale.
Resource hierarchy
Azure Cosmos account
unique DNS name for managing Regions using the Portal, CLI, or SDKs.
- Soft Limit:
50 AZ Cosmos accounts/subscription
Cosmos databases
A database is the unit of management for a set of Azure Cosmos
containers.
Container
Logical Unit containing DataItems in Cosmos databases
Throughput Mode:
Provisioned unlimited throughput (RU/s) and storage on a container.
1. Dedicated provisioned throughput mode
exclusively reserved throughput for container backed by SLAs.
2. Shared provisioned throughput mode:
shared throughput with the other “shared throughput” containers.
Azure Cosmos items
Smallest Unit for storing Data in Container
| Cosmos entity | SQL | Cassandra | MongoDB | Gremlin | Table |
|---|---|---|---|---|---|
| Database | Database | Keyspace | Database | Database | NA |
| Container | Container | Table | Collection | Graph | Table |
| Cosmos item | Item | Row | Document | Node or edge | Item |
Partitions
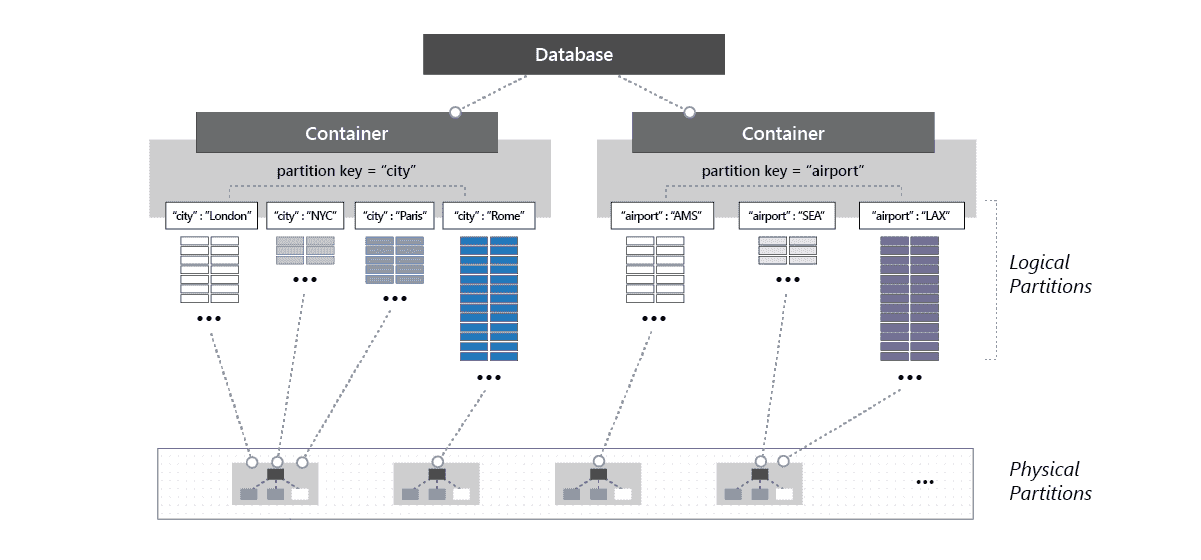
Logical Partition
Group of similar elements with the same
partition key(data key)
Common key value pair in each data item which can distinguish similar items
Choosing a partition key is an important decision that will affect application's performance. A partition key should:
-
Immutable: If a property is partition key, you can't update that property's value.
-
High cardinality: Property should have a wide range of possible values.
-
Spread request unit (RU): Avoid hot partition
Hot partitions: not evenly distributed key might result in too many requests directed to small subset of partitions that become "hot." which might result in rate-limiting and higher costs.
synthetic partition key.
Combined data key to create unique ID
- Common Technique: Concatenate 2 values or add random suffix
Physical partitions
internal implementation of the system and they are entirely managed by Azure Cosmos DB.
- ! Physical partition can have 1 or many Logical Partition
- Limit: 10,000 RU/s & store up to 50GB data
Consistency Levels
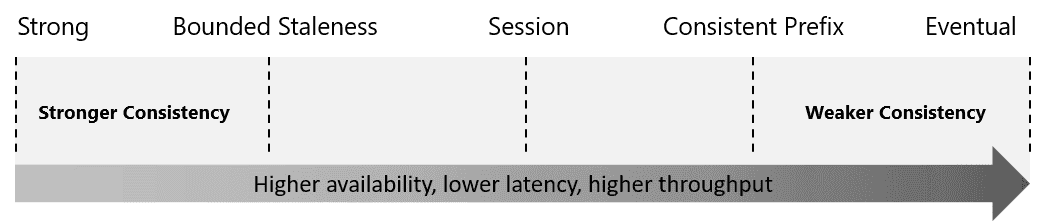
1. Strong
reads are guaranteed to return the most recent committed version of an item.
- the staleness window is equivalent to zero, and the clients are guaranteed to read the latest committed value of the
write operation.

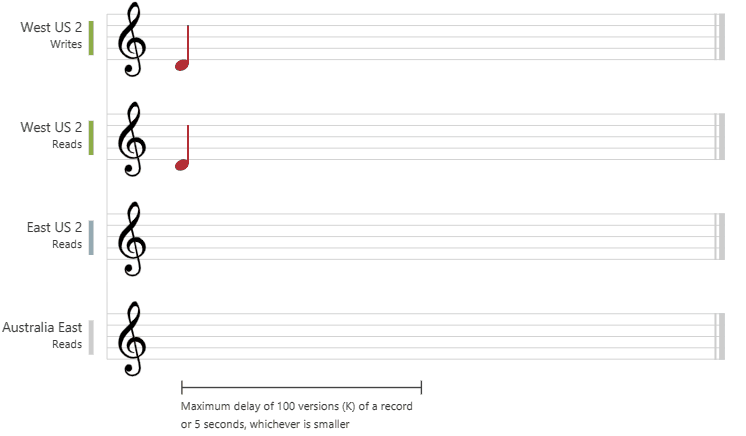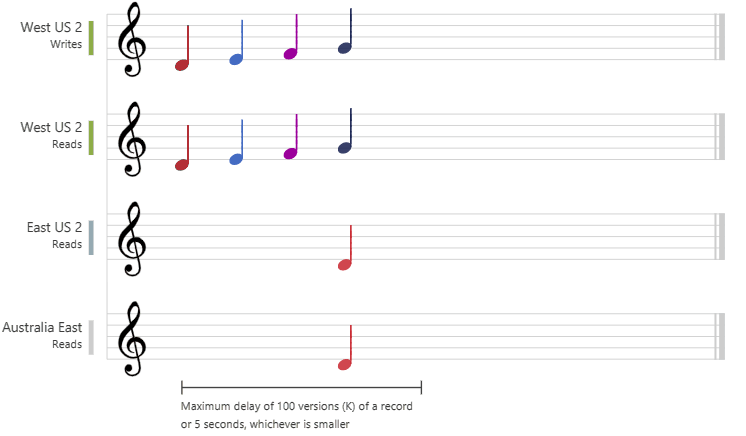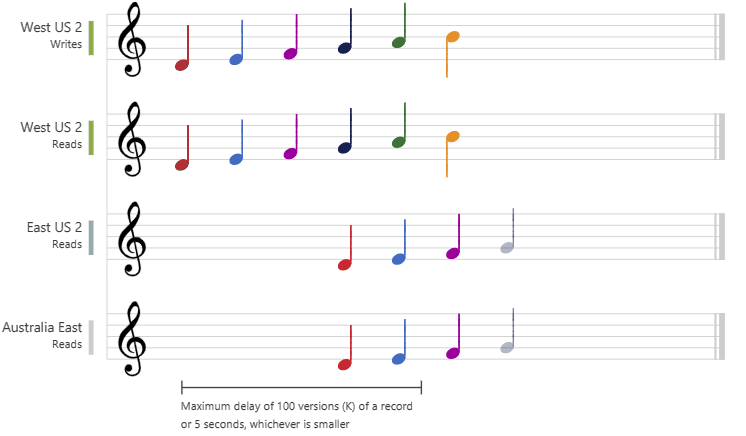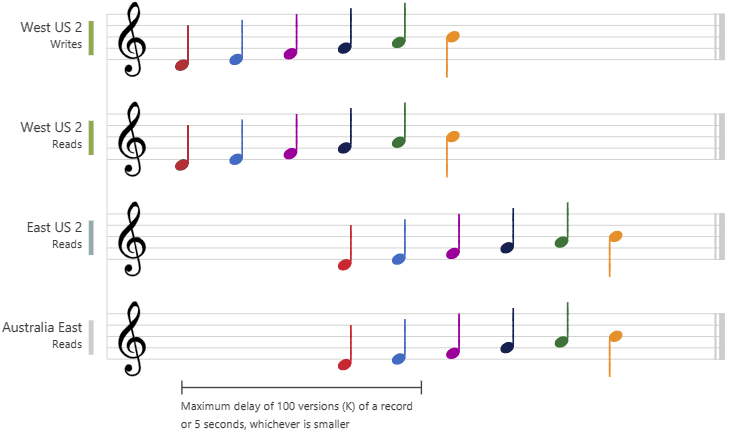
2. Bounded Staleness
Cosmos DB guarantees that the clients always read the value of a previous write, with a lag bounded by the staleness window.
- is for low write latencies but requires a total global order guarantee.
staleness
Can be configured in two ways:
- The number of versions (
K) of the item- min
10for same region - min
100kOps for multi-region
- min
- The time interval (
T) reads might lag behind the writes- min
5 Secfor same region - min
300 secondsfor multi-region
- min
if there are no write operations on the database, a read operation with eventual, session, or consistent prefix consistency levels is likely to yield the same results as a read operation with strong consistency level.
3. Session
Client read latest copy in given session
- Guaranteed read consistent-prefix, monotonic reads, monotonic writes, read-your-writes, and write-follows-reads guarantees.

4. Consistent Prefix
provides the order guarantees that suit the needs of scenarios where order is important.
- write latencies, availability, and read throughput comparable to that of
Eventualconsistency
5. Eventual
No ordering guarantee for reads.
- Offers the greatest throughput at the cost of weaker consistency.

Use: for any web, mobile, gaming, and IoT applicationthat needs
Stored procedures
Can create, update, read, query, and delete items inside an Azure Cosmos container.
-
JavaScript Functions taking
JSONstrings as Input -
All collection functions return a Boolean value that represents whether that operation will complete or not
function createSampleDocument(documentToCreate, arr) { var context = getContext(); var collection = context.getCollection(); var accepted = collection.createDocument( collection.getSelfLink(), documentToCreate, function (error, documentCreated) { context.getResponse().setBody(documentCreated.id) } ); if (!accepted) return; } -
Stored procedures are registered per collection, and can operate on any document or an attachment present in that collection.
-
Bounded execution: All function must run in limited time because all Azure Cosmos DB operations must complete within a limited amount of time.
User Defined Function
Custom function be used inside a query.
Trigger:
1. pre-trigger
Run before modifying DB
- Cannot have any input parameters. The request object in the trigger is used to manipulate the request message associated with the operation.
- Usage: Validation
2. post-trigger
Run after Modifying DB
- runs as part of the same transaction.
- An exception during the post-trigger will fail the whole transaction ie. anything committed will be rolled back and an exception returned.
Relational Database(RDS)

[**Azure SQL Database
**](https://docs.microsoft.com/en-us/azure/azure-sql/database/sql-database-paas-overview?view=azuresql)
Fully managed SQL Database engine that handles most of the database management functions such as upgrading, patching, backups, and monitoring without user involvement.
-
Platform as a service (PaaS) database engine.
-
Serverless: Auto as upgrading, patching, backups, and monitoring
-
Highly Available: 99.99 percent availability
-
Upto Date: run latest stable version of the Microsoft SQL Server database engine.
- allow advanced query processing features, such as high-performance in-memory technologies and intelligent query processing.
- newest capabilities of SQL Server are released first to SQL Database, and then to SQL Server itself.
-
process both relational data and non-relational structures, such as graphs, JSON, spatial, and XML.
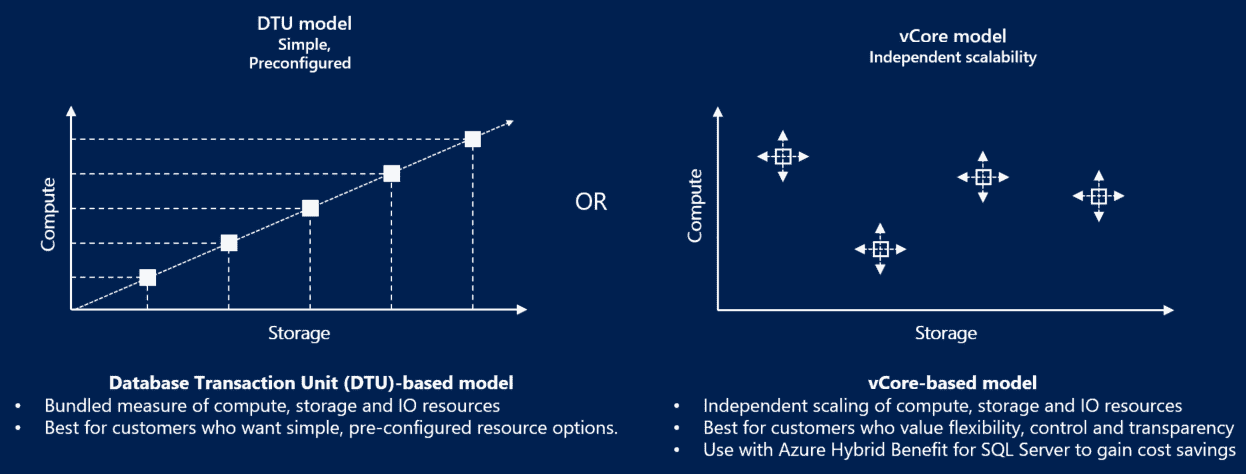
Scale performance
Database transaction unit (DTU) represents a blended measure of CPU, memory, reads, and writes.
1. vCore-based purchasing model
Independently choose compute and storage resources.
2. DTU-based purchasing model.
Use database transaction unit (DTU) to calculate and bundle compute costs.
- Offers a set of preconfigured bundles of compute resources and included storage to drive different levels of application performance.
Azure Database for MySQL
Fully managed
Latest Community edition MySQLthat provides maximum control and flexibility for database operations
- Zone redundant and same zone high availability.
- point-in-time restore to recover a server to an earlier state, as far back as 35 days.
- Maximum control with ability to select your scheduled maintenance window.
- Data protection using automatic backups and point-in-time-restore for up to 35 days.
- Automated patching and maintenance for underlying hardware, operating system and database engine to keep the service secure and up to date.
- Predictable performance, using inclusive pay-as-you-go pricing.
- Elastic scaling within seconds.
- Cost optimization controls with low cost burstable SKU and ability to stop/start server.
- Enterprise grade security, industry-leading compliance, and privacy to protect sensitive data at-rest and in-motion.
- Monitoring and automation to simplify management and monitoring for large-scale deployments.
- Industry-leading support experience.
Azure Database for PostgreSQL
Fully managed
PostgreSQLdatabase that automates maintenance, patching, and updates. Provision in minutes and independently scale compute or storage in seconds.
- Built-in high availability with no additional cost (99.99 percent SLA).
- Predictable performance and inclusive, pay-as-you-go pricing.
- Vertical scale as needed, within seconds.
- Monitoring and alerting to assess your server.
- Enterprise-grade security and compliance.
- The ability to protect sensitive data at rest and in motion.
- Automatic backups and point-in-time restore for up to 35 days.
Deployment Model:
1. Single Server
a single-node database service with built-in high availability.
1.1 Basic
light compute and I/O performance workloads.
1.2. General Purpose
a balanced compute and memory with scalable I/O throughput workloads.
1.3. Memory Optimized
for high performance database workloads requiring in-memory performance.
2. Flexible Server
single-zone or zone-redundant high availability.
3. Hyperscale (Citus)
horizontally scales queries across multiple machines by using
sharding
- Supports SQL query parallelization for faster responses on large datasets.
Azure SQL Managed Instance
allows existing SQL Server customers to lift and shift their on-premises applications to the cloud with minimal application and database changes
- features of both SQL Server database engine and Azure SQL
- Automate the migration of existing SQL Server instance to SQL Managed Instance with Azure Data Migration Service
- Azure Hybrid Benefit for SQL Server allows you to exchange existing licenses to get discounted rates on SQL Managed Instance.
CACHING
Azure Cache for Redis
both the Redis open-source (OSS Redis) and a commercial product from Redis Labs (Redis Enterprise) as a managed service.
- It provides secure and dedicated Redis server instances and full Redis API compatibility.
- Managed Service: operated by Microsoft, hosted on Azure, and usable by any application within or outside of Azure.
Cache Name
- Must be globally Unique
- Length:
1 and 63 characters, alphanumeric '-' - Can't start or end with the '-'
- Consecutive '-' characters aren't valid.
Cache Location
- Put the Redis cache in same Region as DB and close to the data consumer to reduce latency.
Cache Tiers
- All Tier support
Azure Private Linkto access them via internal Azure Network - All 3 Premium Tiers support:
Zone redundancy,Redis data persistence,Redis cluster,Geo Replication - Only Premium Tier support:
Virtual Network Security - Only Enterprise Tier support advance features:
RediSearch, RedisBloom, RedisTimeSeries - Enterprise Flash is
Redis on Flashto save cost.
| Tier | Description | Usage | Limit | Types |
|---|---|---|---|---|
| Basic | OSS Redis cache running on a single VM. No SLA |
Development/test and non-critical workloads. | 250 MB-53 GB, Max 20K Connections. |
C0-C6 |
| Standard | OSS Redis cache running on 2 VMs, replication and Include SLA |
Production cache | 250 MB-53 GB, Max 20K Connections. |
C0-C6 |
| Premium | High-performance OSS Redis caches deployed on more powerful VMs |
Higher throughput, lower latency, better availability, and more features. | 6-120GB, Max 40K Connection |
P0-P4 |
| Enterprise | High-performance caches powered by Redis Labs' Redis Enterprise software. |
Supports Redis modules including RediSearch, RedisBloom, and RedisTimeSeries. Even higher availability than the Premium tier. | 12-100GB, Max 200K Connection |
P0-P4 |
| Enterprise Flash | Cost-effective large caches powered by Redis Labs' Redis Enterprise software |
Extends Redis data storage to non-volatile memory, which is cheaper than DRAM, on a VM. | 384 GB-1.5 TB, Max 120K Connection |
P0-P4 |
Persistance
- Only Supported by Premium, Enterprise & *Enterprise Flash
RDB (Redis Database)
Performs point-in-time snapshots of your dataset at specified intervals.
- Faster restarts with big datasets compared to AOF.
- More compact than AOF and easy to carry around
- NOT good if you need to minimize the chance of data loss
- Snapshot slow down Redis significantly for a few seconds
AOF (Append Only File)
Logs every write operation received by the server, that will be played again at server startup, reconstructing the original dataset.
- Usually bigger than the equivalent RDB files
- All records persisted
TTL
When the TTL elapses, the key is automatically deleted, exactly as if the DEL command were issued.
-
Can be set using
seconds or millisecondsprecision. -
Time resolution is always
1 millisecond.ping: Ping the server. Returns "PONG". set [key] [value] : Sets a Key/Value pair returns "OK" on success. get [key]: Get value of Key exists [key]: Returns '1' if the key exists else '0' type [key]: Returns the type of Value in Key. incr [key]: Increment Value of Key by '1' for integer or double value & returns new value. incrby [key] [amount]:Increment Value of Key by 'anount' for integer or double value & returns new value del [key]: Delete a Key/Value pair flushdb: Delete all Key/Value pairs
ANALYTICS & BIG DATA
https://azure.microsoft.com/en-in/product-categories/analytics/
Azure SYNAPSE ANALYTICS
Limitless analytics service that brings together enterprise-data warehousing and big-data analytics.
- Formerly
Azure SQL Data Warehouse - Query data using either serverless or provisioned resources at scale.
- Unified experience to ingest, prepare, manage, and serve data for immediate business intelligence and machine learning needs.
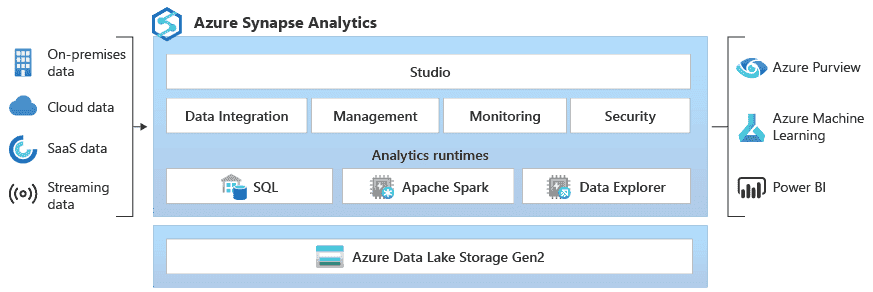
Azure HDInsight
Fully managed, open-source analytics service for enterprises.
- Makes it easier, faster, and more cost-effective to process massive amounts of data.
- Cluster Supports:
Apache Spark, Apache Hadoop, Apache Kafka, Apache HBase, Apache Storm,and Machine Learning Services. - Supports extraction, transformation, and loading (ETL), data warehousing, machine learning, and IoT.
Azure DATABRICKS
Based on
Apache Sparkcapabilities to provide an interactive workspace and streamlined workflows.
- insights from data and build artificial intelligence solutions.
- Setup
Apache Sparkenvironment in minutes, then autoscale and collaborate on shared projects in an interactive workspace. - Supports:
Python, Scala, R, Java and SQL, TensorFlow, PyTorch and scikit-learn.
Azure DATA LAKE ANALYTICS
On-demand analytics job service that simplifies big data.
- With no infrastructure to manage, you can process data on demand, scale instantly and only pay per job.
- Use queries to transform data and extract valuable insights & scale instantly
- run massively parallel data transformation and processing programmes
- Supports:
U-SQL, R, Python and .NETover petabytes of data.
Azure STREAM ANALYTICS
provides real-time analytics and a complex event-processing engine.
- Simultaneously analyze and process large volumes of streaming data from multiple sources.

Azure Database Migration Service
Speeds up the migration of your data to Azure.
- Seamless migrations from multiple database sources.
- Migrates with minimal downtime.
- Supports:
Microsoft SQL Server, MySQL, PostgreSQL, MongoDB, and Oracle - Works with both database and data warehouse.
Use case:
- Automate the migration of data with Azure PowerShell.
- Use Azure Migrate to discover your on-premises data estate and assess migration readiness.
Notes:
- To perform an online migration, you need to create an instance based on the premium pricing tier.
- You can create up to 2 DMS services per subscription.
Pricing
- Offline migrations of the DMS Standard tier are free to use.
- DMS premium tier is billed at an hourly rate based on the provisioned compute capacity.
Appendix
DATABASE
| DB | AWS | Azure | Google Cloud |
|---|---|---|---|
| Blockchain | Amazon Managed Blockchain, Amazon Quantum Ledger Database (QLDB) | Microsoft Azure Confidential Ledger (Azure Blockchain Service, Development Kit & Workbench were retired in 2021) | N/A |
| Caching | Amazon ElastiCache (Memcached, Redis) | Azure Cache for Redis, Azure HPC Cache | Cloud Memorystore |
| NoSQL: Column-family | Amazon Keyspaces (for Apache Cassandra) | Azure Cosmos DB, Azure Managed Instance for Apache Cassandra | Cloud Bigtable |
| NoSQL: Document | Amazon DocumentDB (with MongoDB compatibility), Amazon DynamoDB | Azure Cosmos DB | Cloud Firestore, Firebase Realtime Database |
| NoSQL: Graph | Amazon Neptune | Azure Cosmos DB Gremlin API | N/A |
| NoSQL: Key-value | Amazon DynamoDB, Amazon Keyspaces | Azure Cosmos DB, Table storage | Cloud Bigtable, Firestore |
| Relational database management system | Amazon Aurora, Amazon RDS (MySQL, PostgreSQL, Oracle, SQL Server, MariaDB), Amazon RDS on VMware | Azure Database (MySQL, MariaDB, PostgreSQL), Azure SQL (Database, Edge, Managed Instance) | Cloud SQL (MySQL, PostgreSQL, SQL Server), Cloud Spanner |
| Time-series database | Amazon Timestream | Azure Time Series Insights | Cloud Bigtable |
Analytics & BigData
| Analytics | AWS | Azure | Google Cloud |
|---|---|---|---|
| Big data processing | Amazon EMR | Azure Databricks, Azure HDInsight | Dataproc |
| Business analytics | Amazon QuickSight, Amazon FinSpace | Power BI Embedded, Microsoft Graph Data Connect (preview) | Looker, Google Data Studio |
| Data lake creation | Amazon HealthLake (preview), AWS Lake Formation | Azure Data Lake Storage | Cloud Storage |
| Data sharing | AWS Data Exchange, AWS Lake Formation | Azure Data Share | Analytics Hub (preview), Cloud Dataprep (partnership with Trifacta) |
| Data warehousing | Amazon Redshift | Azure Synapse Analytics | BigQuery |
| ETL | AWS Glue, Amazon Kinesis Data Firehose, Amazon SageMaker Data Wrangler | Azure Data Factory | Cloud Data Fusion, Dataflow, Dataproc |
| Hosted Hadoop/Spark | Amazon EMR | Azure HDInsight | Dataproc |
| Managed search | Amazon CloudSearch, Amazon Elasticsearch Service, Amazon Kendra | Azure Cognitive Search, Bing Search API | Cloud Search |
| Managed Kafka | Amazon Managed Streaming for Apache Kafka | Azure Event Hubs for Apache Kafka N | /A (available through a partnership with Confluent) |
| Real-time data streaming | Amazon Kinesis Data Analytics, Amazon Kinesis Data Streams | Azure Stream Analytics | Dataflow, Pub/Sub, Datastream (preview) |
| Query service, data exploration | Amazon Athena, Amazon Elasticsearch Service, Amazon Managed Service for Grafana (preview) | SQL Server ML Services, Big Data Clusters (Spark), Data Lake Analytics, SQL Server Analysis Services, Azure Data Explorer | BigQuery |