
Neural Networks Overview
The Feature Explosion Problem
Why oo we need Neural Networks?
Suppose we have as input features and we want to compute a hypothesis .
We can
For quadratic features
- Quadratic terms grow roughly as
so we will end up with 5000 additional features if we have 100 features.
For cubic features
-
Cubic terms grows as
-
So we will end up with 166,000 additional features if we have 100 features.
As the features become more complex, the number of parameters grows rapidly.
It becomes
- computationally expensive to compute the hypothesis with many features.
- Memory-Heavy to store all the parameters.
- Prone to overfitting due to the large number of parameters.
In this case, we can use a neural network to compute the hypothesis more efficiently.
Practical Example: Image Recognition
Suppose we have a 100 × 100 pixel image as input.
- Each pixel is a feature, so we have
10,000features. - For RGB images, we have 3 color channels, so we have
30,000features.
If we want to compute a hypothesis with quadratic features, we would have on the order of 450 million features, which
is computationally infeasible.
Conclusion
Polynomial logistic regression: Works for small
- Explodes combinatorially for large
- Computationally impossible for large feature sets (like images)
- We need a non-linear model that can capture complex relationships without explicitly generating all polynomial features.
Neural Networks as a Solution
Neural networks can compute complex hypotheses without explicitly generating all polynomial features.
NN Types and Applications
1. Standard Feedforward Networks
Often used for:
- Housing price prediction
- Online advertising
2. Convolutional Neural Networks (CNNs)
Used primarily for
image data
- Exploit spatial structure in images
3. Recurrent Neural Networks (RNNs)
Used for
sequence data
Examples:
- Audio (time series)
- Language (word-by-word sequence)
Custom Neural Networks
Tailored for specific applications Used in complex systems like autonomous driving:
- CNNs for images
- Other components for radar
- Combined into custom architectures
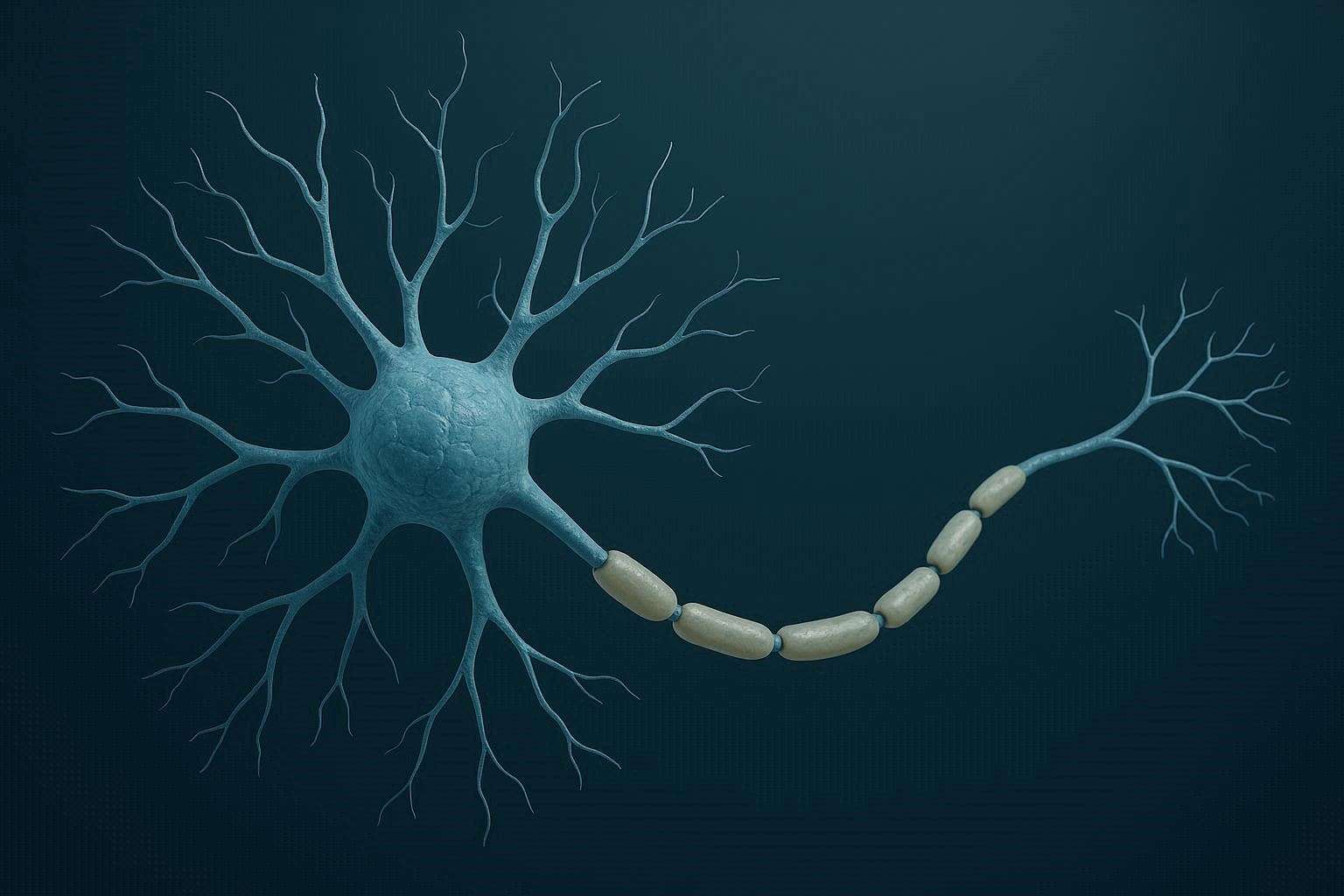
Neurons as Computational Units
At a simple level, neurons are computational units.
They:
- dendrites(head): Take inputs
- Process them: apply weights and activation function
- axon(tail): Produce an output
Artificial Neurons Model: Logistic Unit
In artificial neural networks, we model neurons as mathematical Logistic functions.
graph LR
subgraph Input Layer
x0(((x0)))
x1(((x1)))
x2(((x2)))
x3(((x3)))
end
subgraph Activation Layer
a1{a1}
end
x0-->a1
x1-->a1
x2-->a1
x3-->a1
subgraph Output Layer
y(((hθx)))
end
a1-->y
A simple network looks like:
In our machine learning model:
Inputs are features:
Parameters are called weights
Bias unit
is the bias unit/ bias Neuron and it is always equal to 1
- For simplicity we dont draw
Output
Outputs of neurons are called activations Weights which is the hypothesis
where
And we can rewrite:
so the hypothesis can be expressed as:
is the activation function that introduces non-linearity into the model.
Activation Function ()
is the activation function. for Hypothesis function:
- Example: ReLU, sigmoid
Neural networks using sigmoid activation function for logistic regression:
Where
Where
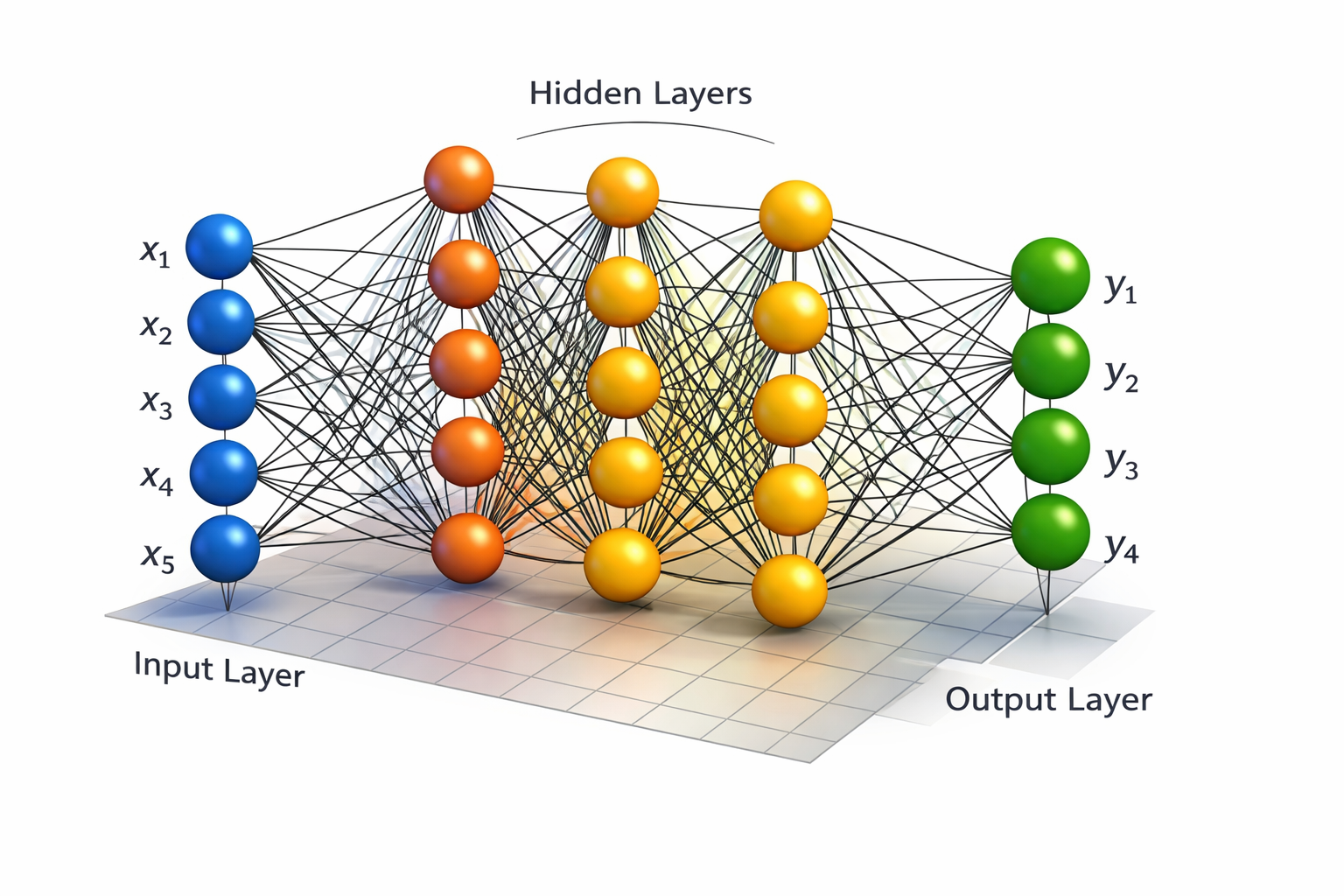
Neural Network Structure
An Artificial Neural Network is a computational graph with layers of artificial neurons.
Neural networks are simply multiple logistic regression units stacked together.
Each layer:
- Takes activations from previous layer
- Multiplies by weight matrix
- Applies sigmoid activation
- Passes result forward
graph LR
Input --> Hidden-Layer
Hidden-Layer --> Output
1. Layer 1: Input layer
Takes features as Input
- = 1 is bias unit that is not drawn
2. Layer 2: Hidden layer:
All Intermediate Layers between Input & Output Layer
- Computes intermediate activations
- =1 is bias unit that is not drawn
= Activation output of th neuron in layer
- = Neuron Index inside that layer
- = layer number
Example:
- = first neuron in Second hidden layer
- = 3rd Neuron in Second hidden layer
Computing Hidden Layer Activations
Activation can be computed as :
Where g(.) is sigmoid
Weight Matrices
Weight Matrix of layer
- weight matrix maps layer to layer
- Each th layer gets its own matrix of weights
- Layers are indexed starting from 1, not 0.
Weight Matrix Dimensions
Outputlayer Neurons x (InputLayer Neurons + 1) Dimensioned Matrix
- Input side includes bias
- Output side does NOT include bias
would be a Matrix of dimension:
Where:
- = number of
neurons/unitsin th layer - units in Output layer
Practical Example:
Each Input Layer is densely connected to each Activation Function of next Layer:
- Input layer: 3 units + 1 Bias
- Hidden layer 1: 4 units + 1 Bias
- Output layer: 1 unit
graph LR
%% ===== Layer 1 =====
subgraph "Layer 1: Input Layer"
x0((x0 = 1))
x1(((x1)))
x2(((x2)))
x3(((x3)))
end
%% ===== Layer 2 =====
subgraph "Layer 2: Hidden Layer"
a0{a0 = 1}
a1{a1}
a2{a2}
a3{a3}
a4{a4}
end
%% ===== Layer 3 =====
subgraph "Layer 3: Output Layer"
y(((hθx)))
end
%% Input → Hidden
x0 --> a1
x0 --> a2
x0 --> a3
x0 --> a4
x1 --> a1
x1 --> a2
x1 --> a3
x1 --> a4
x2 --> a1
x2 --> a2
x2 --> a3
x2 --> a4
x3 --> a1
x3 --> a2
x3 --> a3
x3 --> a4
%% Hidden → Output
a0 --> y
a1 --> y
a2 --> y
a3 --> y
a4 --> y
Simplified
Showing Bias unit but only 1 connection for reference
graph LR
x0(((x0))) --> a1{a1}
x1(((x1))) --> a1{a1}
x1 --> a2{a2}
x1 --> a3{a3}
x1 --> a4{a4}
x2(((x2))) --> a1
x2 --> a2
x2 --> a3
x2 --> a4
x3(((x3))) --> a1
x3 --> a2
x3 --> a3
x3 --> a4
a0{a0} --> y(((hθx)))
a1 --> y
a2 --> y
a3 --> y
a4 --> y
Given
- Input layer:
- Hidden layer:
- Output layer:
Where:
- → bias unit for the input layer
- → bias unit for the hidden layer
Weight Matrix:
Layer 1 ()
Input Layer → Hidden Layer
=> 4 (a_1, a_2, a_3, a_4) × 4
Layer 2 ()
Hidden Layer → Output Layer
=> 1 (output neuron) × 5
Activation of Neurons in Layer 2
First Neuron in layer 2
Second Neuron in layer 2
Third Neuron in layer 2
Where
- : sigmoid activation function of collective term
3. Output layer
Gives us the final hypothesis
- Hidden layer outputs become inputs to the next layer
- Another weight matrix is applied
- Then the sigmoid function is applied again
Output Layer Hypothesis
The final hypothesis is the first neuron of 3rd layer
Which is equals to
Where
- : Sigmoid of final term
- is weight Matrix for final Output Layer