
Bias-Variance Dilemma
Understanding the bias-variance tradeoff in machine learning, including the concepts of bias and variance, underfitting and overfitting, and strategies to balance model complexity for better generalization.
Evaluating a Hypothesis in Neural Networks
Cost Function Regularization: Balancing Bias and Variance in Machine Learning Models
Bias-Variance Dilemma
Ideally, one wants to choose a model that both accurately captures the regularities in its training data, but also generalizes well to unseen data.
When a model performs poorly, the key question is:
Is the problem bias or variance?
- High bias → underfitting
- High variance → overfitting
Our goal is to find the balance between the two.
🔬 Diagnosing Bias vs. Variance
Effect of Polynomial Degree
As degree of polynomial increases:
📚 Training error :
- steadily decreases
- Higher-degree models fit the training data better
📘 Cross-validation error
- decreases, then increases
- Forms a convex (U-shaped) curve
Low → High bias
High → High variance
Middle → Good balance
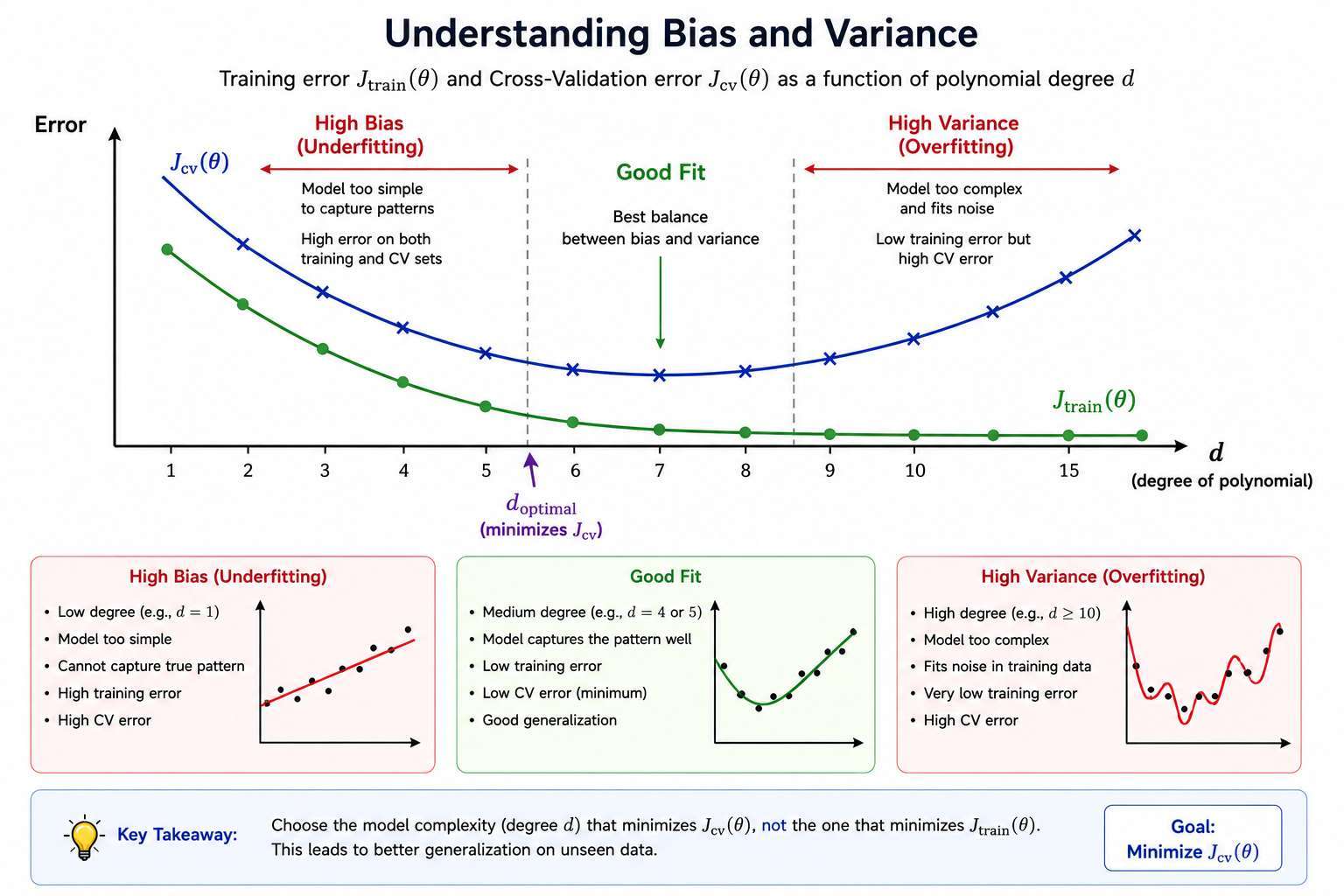
This behavior helps us diagnose bias vs. variance.
Practical Diagnostic Rule
| Situation | Diagnosis | ||
|---|---|---|---|
| Both high and similar | High | High | High bias |
| Large gap (train low, CV high) | Low | High | High variance |
| Both low and similar | Low | Low | Good fit |
Bias vs Variance Summary
| Concept | Meaning | Cause | Effect |
|---|---|---|---|
| High Bias | Model too simple | Too few features | Underfitting |
| High Variance | Model too complex | Too many features | Overfitting |
High Bias (Underfitting) 🦎
The model is too simple to capture the underlying pattern of the data
Characteristics:
- Model is too simple
- Fails to capture structure in the data
- Adding more data does not help much
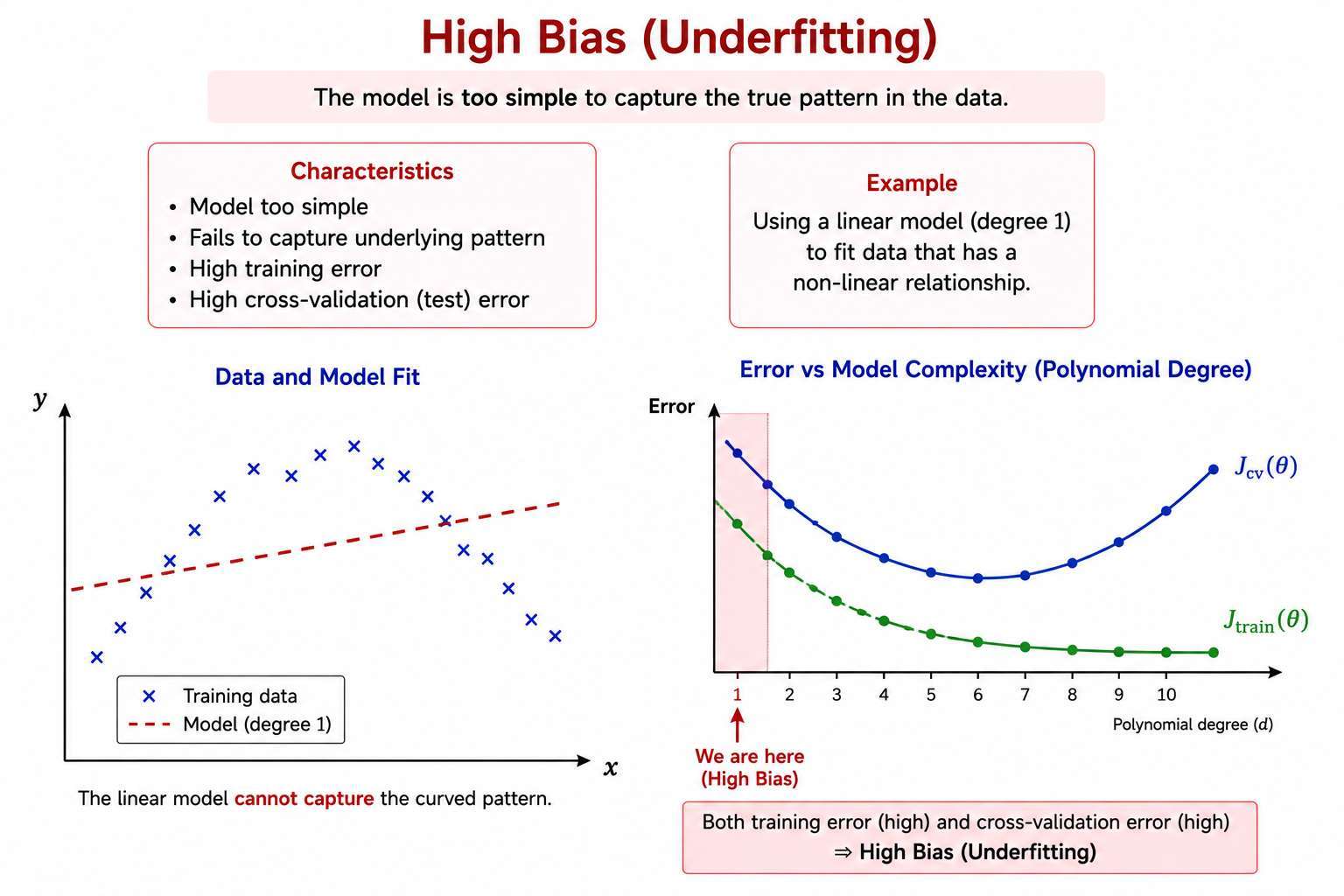
Costs
-
is high
-
is also high
Problem:
- Poor training performance
High error as equation does not cover all dataset
- Poor Test performance
Fail when new data set introduced
- The model performs poorly everywhere
Interpretation:
- Adding more data usually does not help much
- Increasing model complexity() may help
🪱 High Variance (Overfitting)
model is too complex and starts fitting the training data perfectly
- Model can bend heavily to pass through every training point.
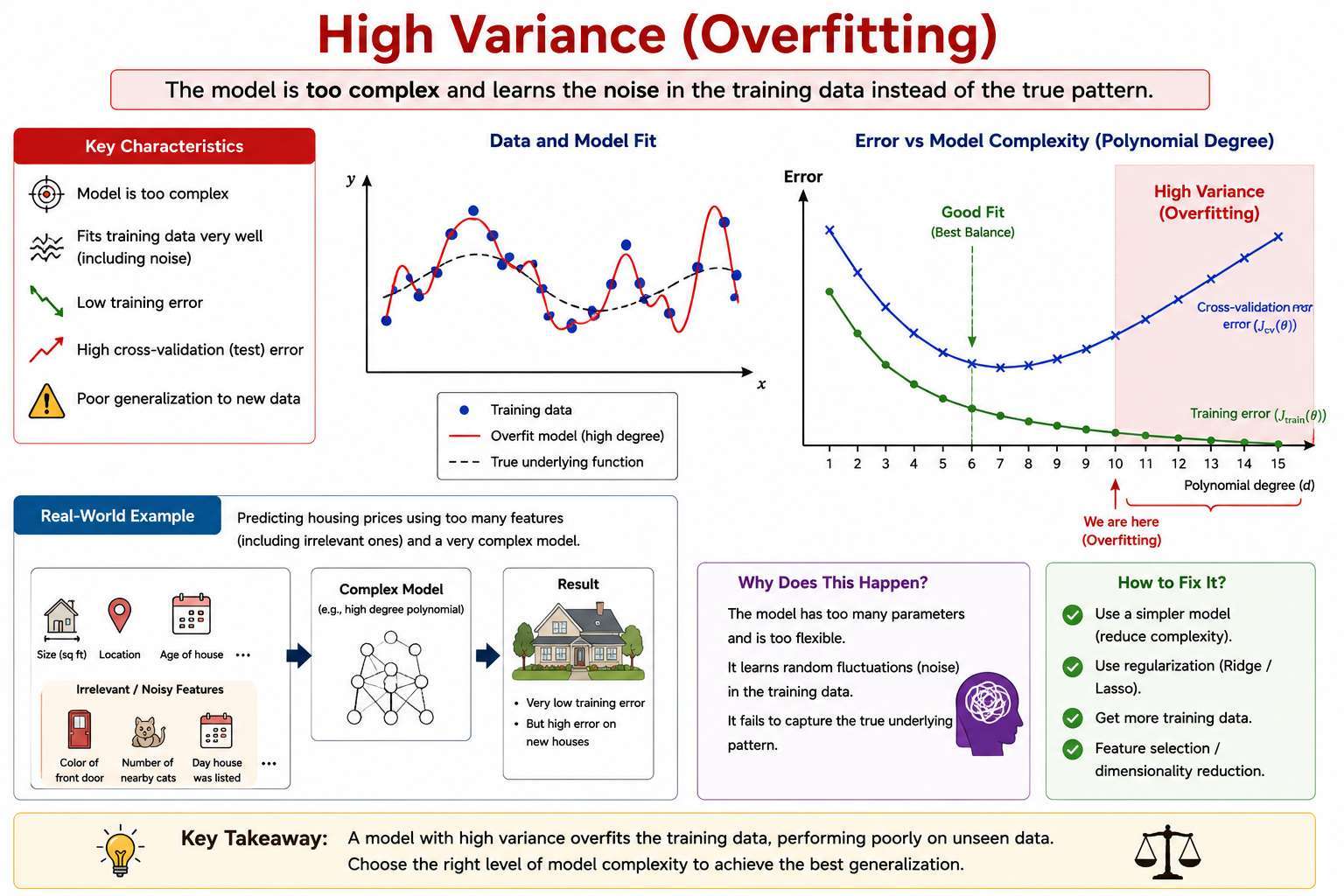
Characteristics:
- Model is too complex
- Fits noise in the training data
- Adding more data can help reduce variance
- is low, but is high
Problem:
Low training error ie. good training performance
Poor test performance lead to poor performance on unseen data.
- Poor generalization to new data
Interpretation:
- Model performs very well on training data
- Performs poorly on unseen data
- Large gap between training and validation error
Solutions
- Use Regularization term to add Penalty for features
- Reduce model complexity:
- Reduce Number of Features: Manually select important features
- Remove irrelevant variables
- Use automated model selection methods
- Add more training data to help the model learn the true underlying pattern and reduce overfitting.
Key Insight
- Bias is about model simplicity.
- Variance is about model sensitivity to data.
Good model selection is about finding the degree that minimizes:
while avoiding both underfitting and overfitting.