
Anomaly Detection Using Gaussian Distribution in Machine Learning
Learn how anomaly detection works using the Gaussian (normal) distribution. Understand how to model data probabilistically, estimate parameters, compute likelihoods, and identify outliers using threshold-based decision making in machine learning systems.
Anomaly Detection: Identifying Rare and Unusual Patterns in Data
Anomaly Detection Using Multivariate Gaussian Distribution
Anomaly Detection Using Gaussian Distribution
In this approach, we build an anomaly detection algorithm by modeling the probability of data using Gaussian distributions.
- Model each feature using a Gaussian distribution.
- Estimate and from training data.
- Compute for new examples.
- Flag examples where:
Low probability → likely anomaly.
🔔 Understanding Gaussian Distribution
Probability Density Function
The Gaussian probability density function is:
Where:
- = random variable in data set
- = mean : average of all data points
- = standard deviation : how much data varies from the mean
- = variance : square of standard deviation
Shape of the Gaussian Distribution
The Gaussian curve has the following properties:
- It is bell-shaped
- It is symmetric around the mean
- The total area under the curve equals 1
When plotted:
Any random variable follows a Gaussian distribution with:
Where
The symbol means “is distributed as”.
Effect of Parameters
The curve is fully defined by two parameters. So our goal is to estimate:
Normal case: μ = 0, σ = 1
This is the standard normal distribution.
- Centered at 0
- Moderate width
1. Mean (μ) ↔️
The average of all the data points
- Controls the center of the distribution.
- Changing μ shifts the curve left or right.
Example:
- If μ = 0 → centered at 0
- If μ = 3 → centered at 3
Effect of ↔️
| Shape of the Curve | ||
|---|---|---|
| 0 | 1 | Standard bell curve |
| 3 | 1 | Shifted to the right, same shape as standard curve |
| -2 | 1 | Shifted to the left, same shape as standard curve |
2. Standard Deviation () ↕️
This measures how far the data points are from the mean.
It is the average squared deviation from the mean.
- Controls the width of the curve.
- Smaller → narrower and taller curve
- Larger → wider and flatter curve
Since total area must equal 1:
- If the curve gets wider → it becomes shorter
- If the curve gets narrower → it becomes taller
Effect of ↕️
| Shape of the Curve | ||
|---|---|---|
| 0 | 1 | Standard bell curve |
| 0 | 0.5 | Narrower and taller curve |
| 0 | 2 | Wider and flatter curve |
Note on 1/m vs 1/(m−1)
In statistics, you may sometimes see:
instead of:
In machine learning, we usually use 1/m. When the dataset is large, the difference is very small in practice.
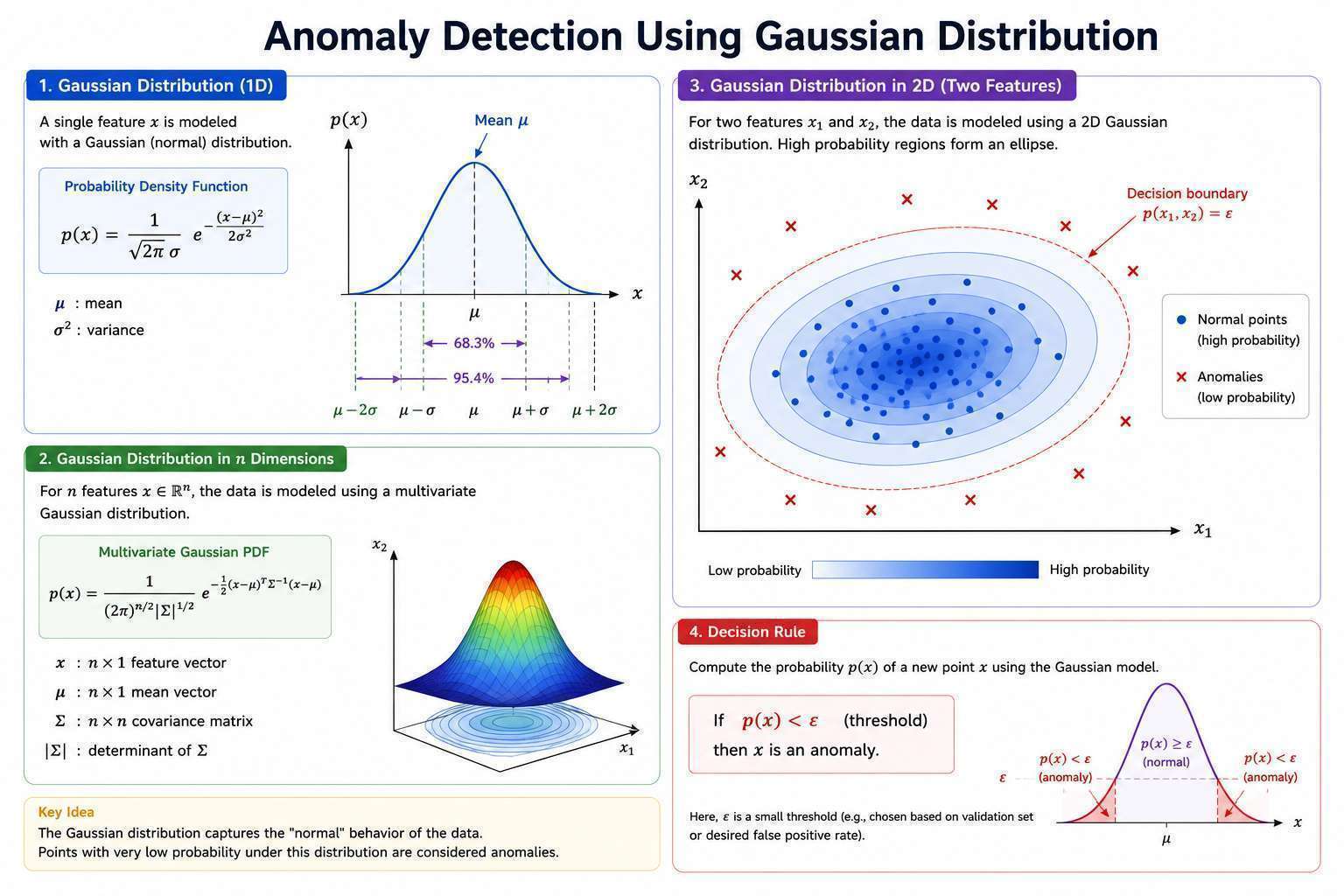
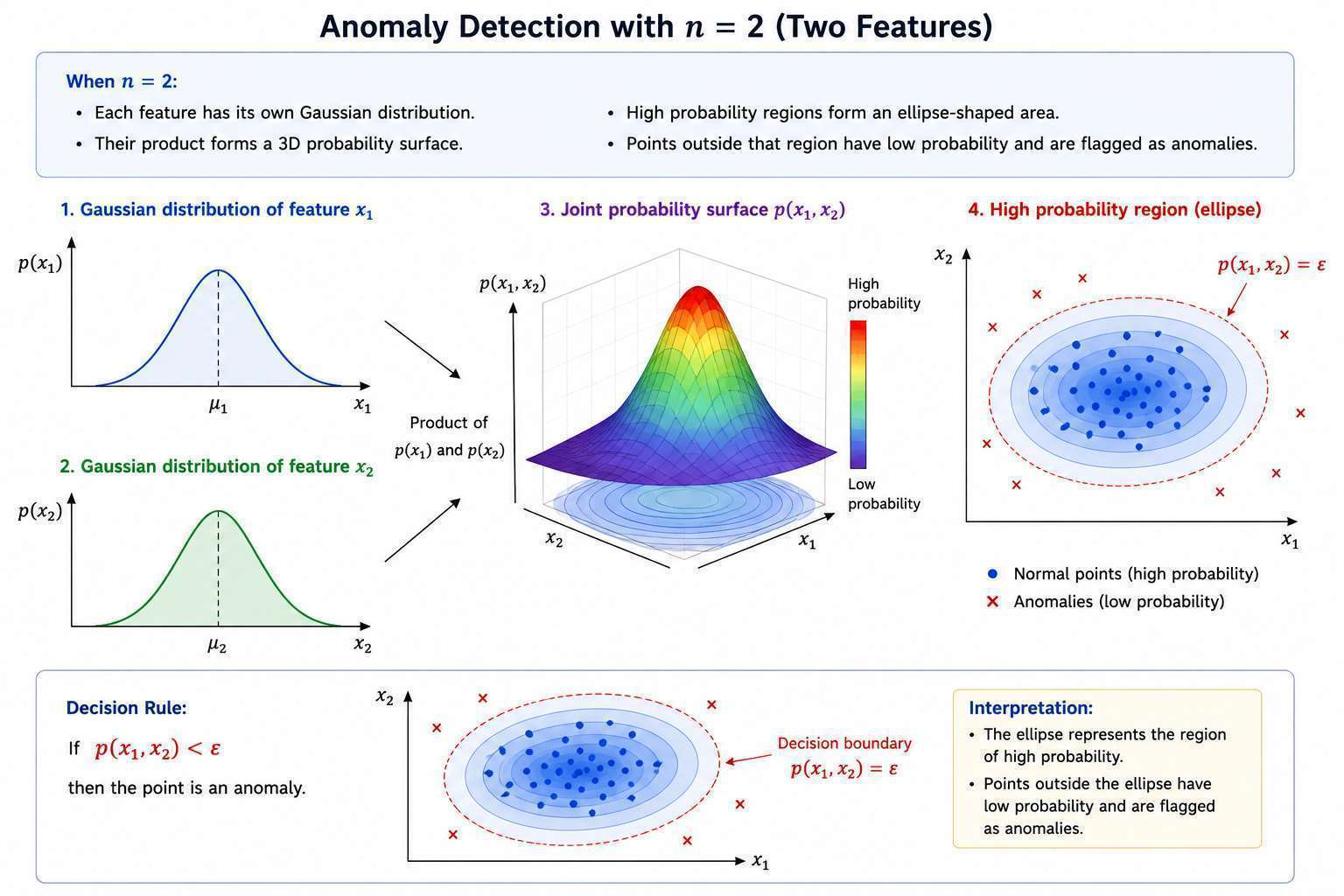
Intuition (2D Case)
When :
- Each feature has its own Gaussian distribution.
- Their product forms a 3D probability surface.
- High probability regions form an ellipse-shaped area.
- Points outside that region have low probability and are flagged as anomalies.
Problem Setup
We are given:
-
An unlabeled training set of examples:
-
Each example is a feature vector in
Examples:
- Aircraft engine sensor data
- User behavior features
- System monitoring metrics
The goal is to determine whether a new example is normal or anomalous.
1. Training Phase 📚
- Choose relevant features.
- Compute .
- Compute .
Modeling
We model the probability of a data point using Gaussian Distribution:
where is the number of features.
Each feature is modeled using a Gaussian distribution:
The symbol means “is distributed as”.
This means the random variable follows a Gaussian distribution with:
- Mean
- Variance
1. Parameter Estimation
Given training data, we estimate parameters.
Mean
For each feature :
This is the average value of feature .
Variance
This measures how spread out the feature values are.
2. Density estimation 🌌
Compute Probability of Examples
Probabilities are multiplicative for independent features.
We assume the features are independent, so:
Here, denotes a product (multiplication over a range).
Where each feature probability is:
Example
For a 2-feature example:
Temperature
-
= 17.5
-
Vibration Intensity
- = 48
To find the overall probability of this example:
Therefore:
2. Making Predictions 🔎
Detection Phase
For a new example :
Step 1: Compute probability
Step 2: Choose threshold
Decision Rule
Compare with .
Flag as anomaly if probability is low.
Key Takeaway
This (univariate) approach models each feature's:
Feature Variance
independently, treating features as uncorrelated. It doesn't capture relationships between features — for that, see Multivariate Gaussian Distribution, which adds:
Feature Correlation
which allows anomaly detection systems to detect unusual combinations of features, not just unusual individual values.