
Cost Function Regularization: Balancing Bias and Variance in Machine Learning Models
Learn how cost function regularization helps prevent overfitting in machine learning models by adding a penalty term to the cost function, controlling model complexity, and improving generalization performance.
Bias-Variance Dilemma
Normal Equation in Linear Regression: Formula, Intuition, and Comparison with Gradient Descent
Regularization 🛑
If a model is overfitting, we can reduce the influence of certain terms by increasing their cost. This discourages large weights.
Regularization balances:
- Bias
- Variance
Regularization techniques
Used to make reduce variance and solve problem of Overfitting
-
Instead of removing features, keep them all but reduce parameter sizes.
-
Regularization adds a penalty term to the cost function to discourage complexity.
-
Regularization helps prevent overfitting by keeping the model simpler.
-
The regularization parameter λ controls the strength of the penalty. A larger λ means more regularization.
Instead of removing features, keep them all but reduce parameter sizes.
The idea:
- Large weights → complex model
- Small weights → smoother model
General Regularized Cost Function
In standard linear regression, the cost function is:
Mean Squared Error
Measures how well the model fits the training data.
We Add Regularization Term to it
Regularization term
Penalizes large parameter values to prevent overfitting.
The Regularization term is:
- is the regularization parameter that controls the strength of regularization.
- This term penalizes large values of , encouraging smaller weights and thus simpler models.
The parameter vector contains:
Explicitly excludes the bias term .
- Regularization runs from to
- So is not penalized
Why Exclude ?
The bias term controls the decision boundary shift.
We do not want to shrink it toward zero.
Only the other parameters are regularized.
So effective cost become
We can regularize all parameters using a single summation over to
We dont regularized Bias parameter
Regularization Algos
Lasso vs Ridge
| Feature | Lasso (L1) 🔹 | Ridge (L2) |
|---|---|---|
| Penalty | Sum of absolute values | Sum of squares |
| Effect | Can shrink some coefficients exactly to 0 → feature selection | Shrinks coefficients but rarely to 0 |
| Use Case | Many irrelevant features | Prevent overfitting, keep all features |
1. Lasso Regression (L1 Regularization) 🔹
Lasso: Cost = MSE + λ * sum(|θ|)
- Lasso (L1) can shrink some coefficients to zero, effectively performing feature selection.
Lasso adds a penalty proportional to the sum of absolute values of the coefficients:
Where:
- = regularization strength
- = absolute value of parameter
- (bias) is usually not penalized
2. Ridge Regression (L2 Regularization) 🏔️
Ridge: Cost = MSE + λ * sum(θ^2)
- Ridge (L2) shrinks coefficients but does not set them to zero.
Ridge adds a penalty proportional to the sum of squared coefficients:
Where:
- = regularization strength
- = model parameters
- (bias) is usually not penalized
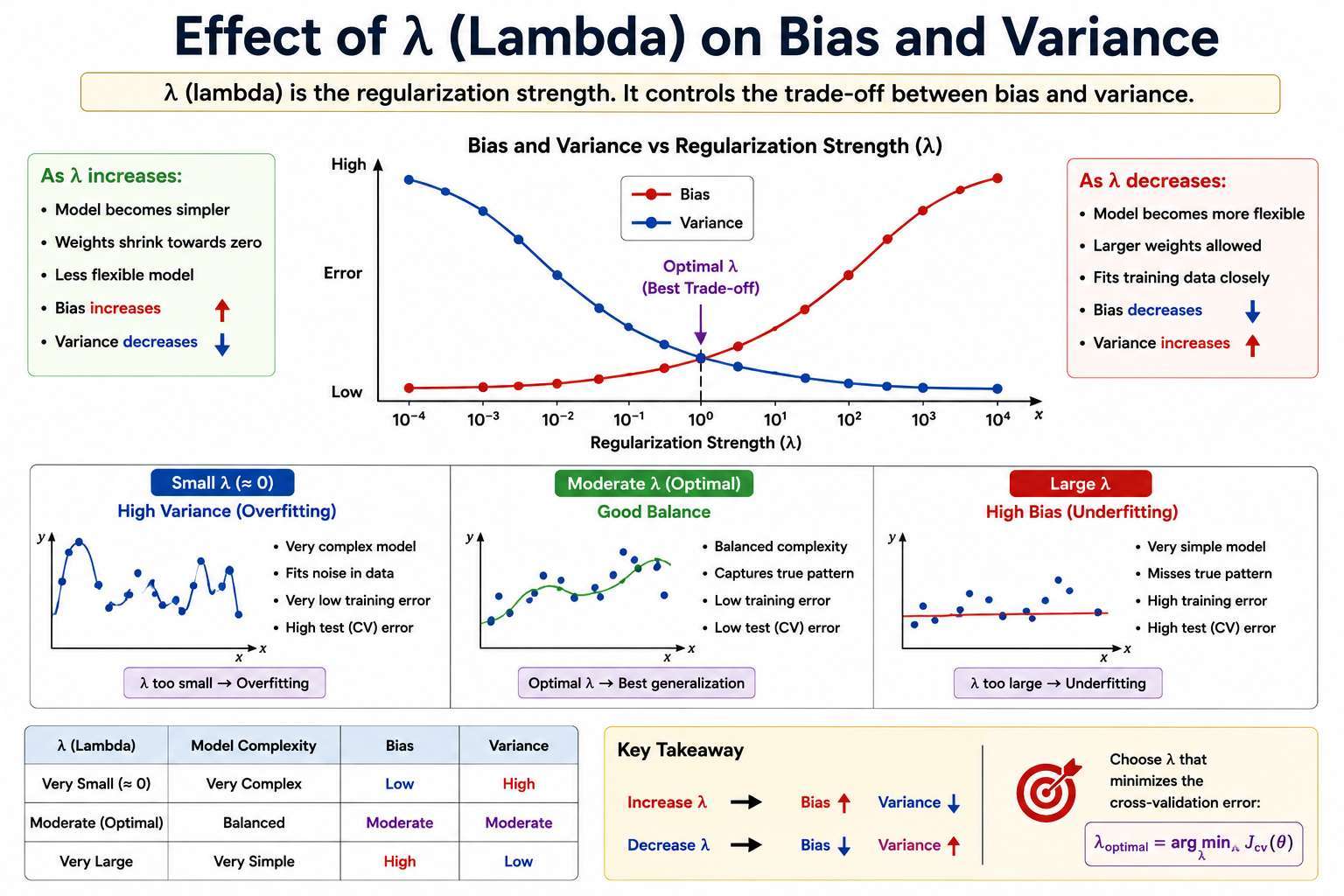
Regularization Parameter
Regularization shrinks parameters. The more shrinkage you see, the larger the
Choosing correctly is essential for good generalization.
The regularization parameter λ (lambda) controls the tradeoff between bias and variance.
| Lambda (λ) | Model Complexity | Bias | Variance |
|---|---|---|---|
| Very Small (0) | Very Complex | Low | High |
| Moderate | Balanced | Moderate | Moderate |
| Very Large | Very Simple | High | Low |
Larger → stronger regularization
→ all parameters shrink to zero → model becomes too simple → underfitting
- Parameter Weights shrink toward zero
- Reduces model complexity and make it rigid/linear
- Underfitting may occur
- Bias increases
- Variance decreases
Example:
Smaller (as )
→ no regularization → model may overfit
weaker regularization --> Less Penalty --> Large weights
- Parameter weights grow larger
- More complex models & becomes more flexible/curvy
- Risk of overfitting
- Variance increases
- Bias decreases
Small λ → Low bias, high variance (overfitting)
Example:
What Happens If ?
- No regularization is applied
- The model may overfit
- We revert to standard least squares / logistic regression
How to Choose the Best λ
To select the optimal regularization parameter:
- Choose candidate λ values
- Train models for each λ
- Compute cross-validation error (without regularization)
- Select best λ + model
- Evaluate once on test set
1. Create Candidate Values
Example:
2. Train Models
For each value of λ:
- Train model parameters Θ
- Possibly try different model complexities (degrees, architectures, etc.)
3. Compute Cross-Validation Error
Evaluate using:
Important:
- Compute cross-validation error without regularization
- That means use λ = 0 when evaluating
This ensures fair comparison between models.
4. Select Best Combination
Choose the model and λ that produce the lowest cross-validation error.
5. Final Evaluation
Using the best:
- Θ
- λ
Evaluate on the test set:
This measures generalization performance.
Example: Polynomial Hypothesis
Consider the function:
If we want the model to behave more like a quadratic function, we can reduce the influence of:
Instead of removing these features, we modify the cost function.
Regularized Cost Function
We minimize:
Effect of Large Penalty
Adding large penalty terms forces:
This reduces the contribution of:
As a result:
- The hypothesis becomes smoother
- Overfitting decreases
- The curve behaves more like a quadratic function